Introduction
One of the main use cases of LangChain is connecting LLMs to user data, allowing users to build personalized LLM applications. A key part of this is retrieval - fetching relevant documents based on user queries.
Today we’re happy to announce the integration of Vectara into LangChain to help make retrieval easier. In this blog post, we’ll dig deeper into why retrieval is so important and how to use Vectara’s LangChain integration to build scalable LLM-powered applications.
What is Vectara?
Vectara is a GenAI conversational search platform, providing an easy-to-use “ChatGPT for your own data'' experience using “Grounded Generation”.
Developers can use Vectara’s API, based on a neural search core, which enables highly accurate matching between queries and relevant documents, to build GenAI conversational search applications, such as our AskNews sample application.
Using Vectara simplifies LLM application development: the search platform does a lot of the heavy lifting of interfacing with user data, letting developers focus on the application logic unique to their product.

Grounded Generation with LangChain
LLMs are extremely powerful models, but they have a problem with data recency and hallucinations. For example, as mentioned in this blog post about LLM hallucinations, if you ask ChatGPT about Silicon Valley Bank, it will provide a response based on the pre-2022 data it was trained on, and will have no idea above the bank’s recent collapse.
“Grounded Generation” is a general approach to address this issue and is one of the main use cases available through LangChain.
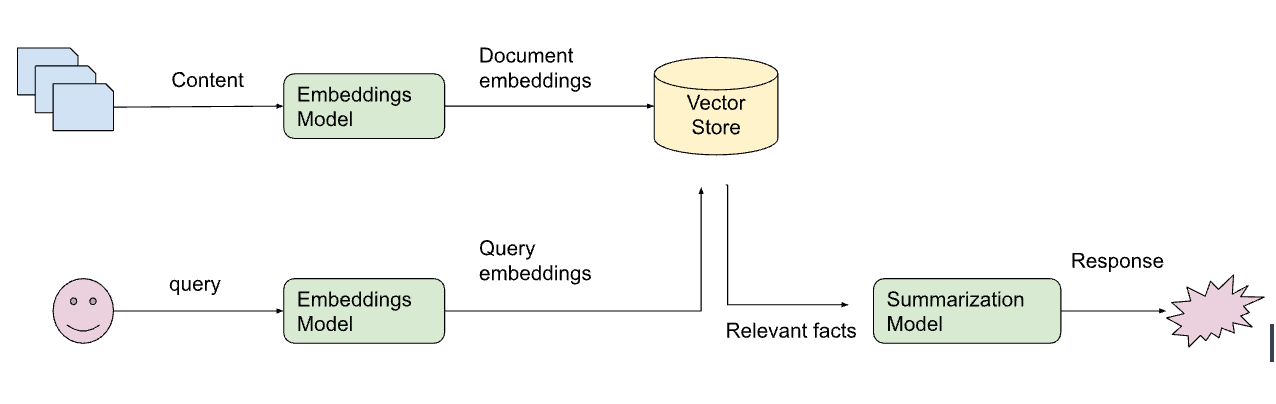
Let’s look at a simple example of question-answering with retrieval augmented generation from the LangChain codebase.
from langchain.document_loaders import TextLoader
from langcain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitters import CharacterTextSplitter
from langchain.vectorstores import FAISS
raw_docs = TextLoader(‘state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(raw_docs)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
qa = RetrievalQA.from_llm(llm=OpenAI(), retriever=vectorstore.as_retriever())First, we take the document text (in this case, a transcript of the 2022 State of the Union) and use langchain.text_splitter.CharacterTextSplitter to split the text into small chunks (1000 characters each).
Then we get embeddings for each chunk using OpenAIEmbeddings, and store them in a vector database like FAISS.
Finally, we build a RetrievalQA ( retrieval question-answer) chain.
And the answer we get is.
“Putin miscalculated that the world would roll over when he rolled into Ukraine.”
Pretty cool!
LangChain question-answering with Vectara
Let’s run the same program, but this time use Vectara as the vector store. Doing this will take advantage of Vectara’s “Grounded Generation”.
First, we set up a Vectara account and create a corpus. After creating an API key for that corpus, we can set up the required arguments as environment variables:
export VECTARA_CUSTOMER_ID=<your-customer-id>
export VECTARA_CORPUS_ID=<the-corpus-id>
export VECTARA_API_KEY=<...API-KEY…>Vectara provides its own embeddings that are optimized for accurate retrieval, so we actually don’t have to use (or pay for) an additional embedding model. Instead, we simply use Vectara.from_documents() to upload the documents into Vectara’s index for this corpus, and use that as a retriever in the chain:
from langchain.vectorstores import Vectara
loader = TextLoader(“state_of_the_union.txt”)
documents = loader.load()
vectara = Vectara.from_documents(documents)
qa = RetrievalQA.from_llm(llm=OpenAI(), retriever=vectara.as_retriever())
print(qa({“query”: “According to the document, what did Vladimir Putin miscalculate?”}))Vectara takes the source documents and automatically chunks it in an optimized manner and creates the embeddings, so we don’t even have to use the TextSplitter (and decide on chunk size), nor do we need to call (or pay for) OpenAIEmbeddings. Since Vectara has its own internal vector storage, we don’t need to use FAISS or any other commercial vector database.
Finally, we build a RetrievalQA (retrieval question-answer) chain in the same way as before, and again we get the response:
“Putin miscalculated that the world would roll over when he rolled into Ukraine.”
Summary
We are excited to have Vectara fully integrated with LangChain, making it easier for developers who already love LangChain to build LLM-powered applications with Grounded Generation.
Big thanks to the Vectara team (Ofer, Amr and many others) for their support and contribution.
If you’d like to experience the benefits of Vectara + LangChain firsthand, you can sign up for a free Vectara account here.