
Editor’s Note: This blog post was written in collaboration LeptonAI Team, an early LangSmith BETA user. Lots of folks are talking about how best to finetune an open-source model for their specific use case, and LeptonAI has actually done that. We're excited to share their journey and hope it can inform others.
Introduction
Have you ever thought about joining an earning call and asking questions to these CFOs? That used to be the privilege held by the investors from high-end investment banks such as JP Morgan, Goldman Sachs and Morgan Stanley.
Yet with the capability of LLM and proper techniques around it, not anymore. And if you don’t feel like reading the whole post, feel free to try out a demo here. This demo is created based on the Apple Q2 2023 earning call.
Step into the realm where cutting-edge technology meets financial acumen, let’s dive deep into the transformative process of harnessing the capability of AI, and unveil the secrets to crafting an AI that speaks like a seasoned Chief Financial Officer (CFO), as demonstrated below.

Problem Statement
To begin with, I would like to breakdown the challenge mentioned above into an abstraction, which hopefully can help you understand at an engineering level on what problem we are facing. In a nutshell, the problem looks like this:
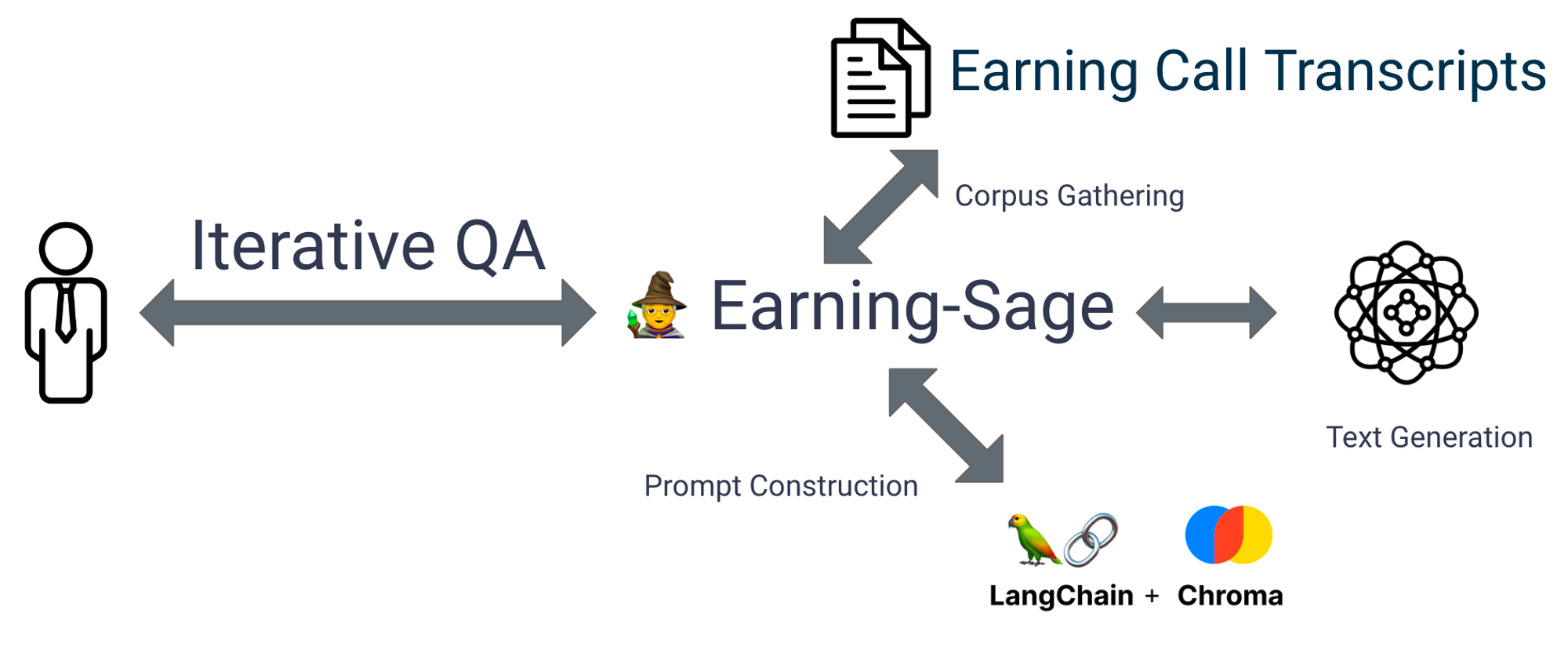
The problem we are facing here is to organically combine the original earning call transcript, the text generation model ( mostly could be OpenAI ChatGPT 3.5) and the toolset(python, langchain, chroma, nothing fancy here) to mimic a CFO.
Thought Through Process for solutions
Starting with openAI
To begin with, I started with using ChatGPT 3.5 from open AI with Langchain retrievalQA chain, which is a pretty standard approach for anyone building out an application like this. With that being said, the solution now looks like this:
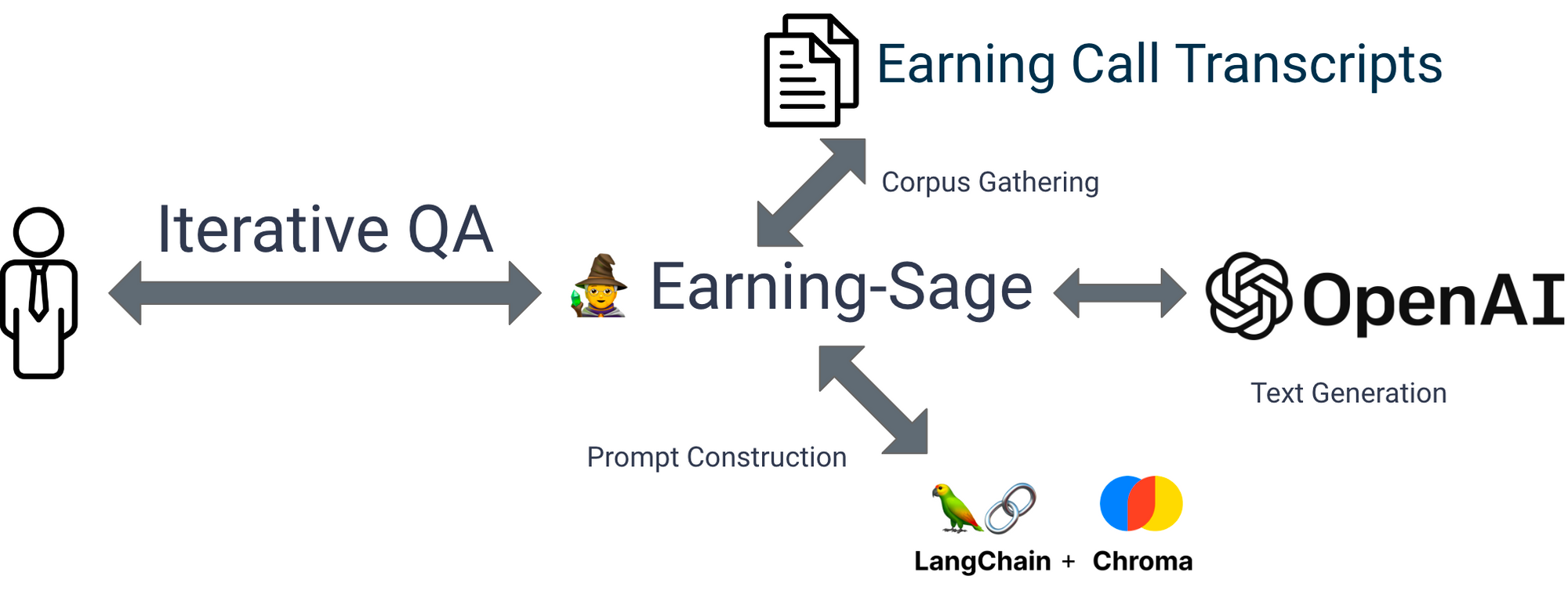
Not surprisingly, ChatGPT 3.5 works quite well for questions simply enough, eg. What's covered in this earning call? . The open source tools works like a charm in terms of prototyping. It doesn’t take long to build up the first version of the product. Yet for questions bit more complicated, ChatGPT gives up very quick. You may check it out here .
The full questions list with response from ChatGPT 3.5 is here
- What's covered in this earning call?
- What is the potential for further growth in the number of Apple devices per iPhone user?
- What is the Apple’s strategy over AI?
- What are the feedbacks on Apply Pay Later?
Then I tried vanilla vicuna
Overheard from friends, and as an Open Source Developer ( worked on Jupyter Lab, yes, the notebook, but beyond notebook! 😅), I decided to try out Vicuna, an open-source chatbot trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. With that being said, the solution now looks like this:
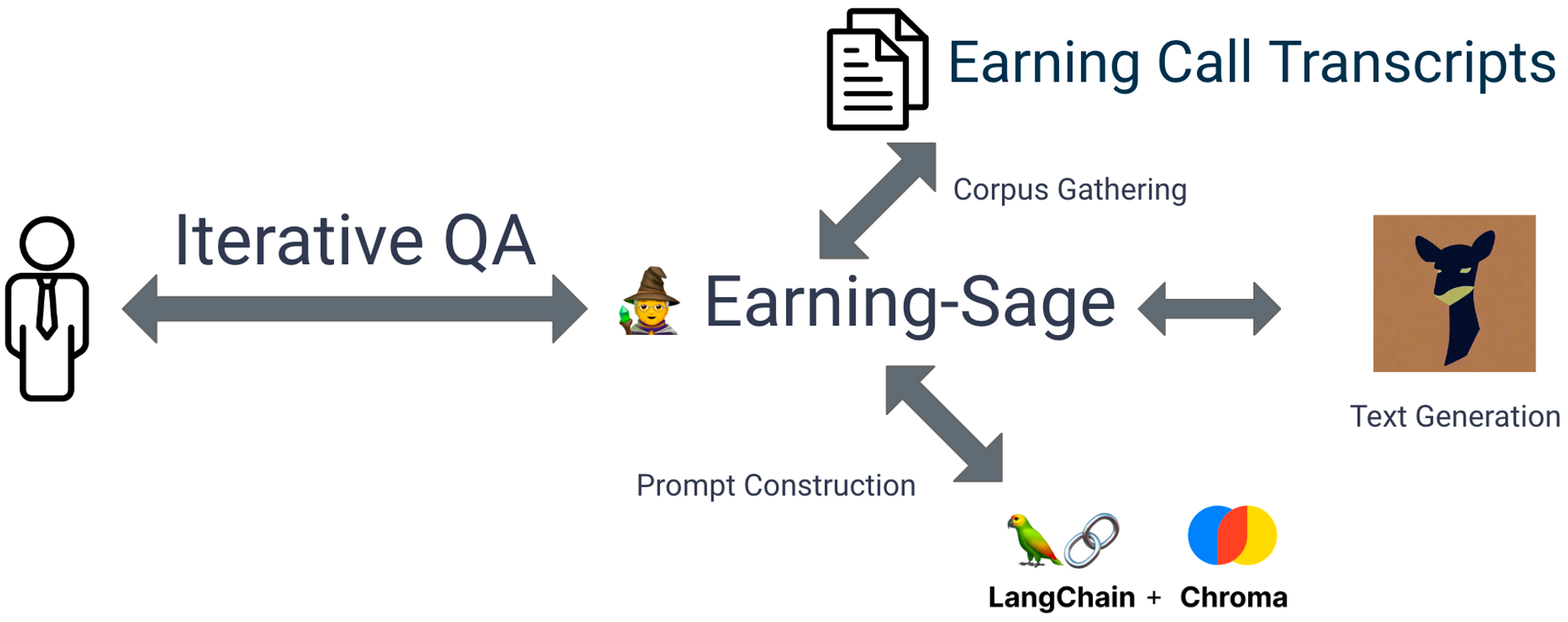
The tricky part here is the first version of the product is built upon Langchain which is initially built upon OpenAI’s API. So as a lot of other prompt engineering frameworks. In this case, switching to another model is a lot of work in terms of compatibility issues. Eg. the other model may doesn’t have the same embedding api endpoint. or the tiktoken lib doesn’t support certain models.
Due to this problem, engineering team at Lepton.AI found a way to make the model compatible with the original OpenAI’s API endpoint, makes switching models for a LLM application much easier. The model service enable users to switch the model by simply altering the environment from
OPENAI_API_BASE=https://api.openai.com/v1
OPENAI_API_KEY=YOUR_OPEN_API_KEY
to
OPENAI_API_BASE=YOUR_DEPLOYMENT_URL
OPENAI_API_KEY=YOUR_LEPTON_AI_API_KEY
The result turns to be pretty solid at first glance, yet evaluation on the outputs is quite challenging. This is where LangSmith comes in handy. It allows me to add four lines of code to alter the environment variables, and it could handle everything for me from there.
Turns out the Fine Tuned model is even better
Even though the vanilla model works by not giving up so fast, it still doesn’t really talk quite like a CFO. That is saying the way it talks does not give me the feeling of actually attending an earning call surrounded by talents from top financial institutions.
Hence inspired by Vicuna, the fine-tuned model of llama, I decided to fine-tune a model that utilize data from the earning call question & answer section. By collecting data from the earning transcripts, I managed to sample out quite a few earning calls. Then using TUNA, a model augmentation service that augment both the data and model, to create a model that’s more focused on earning call context. With that being said, the solution now looks like this:
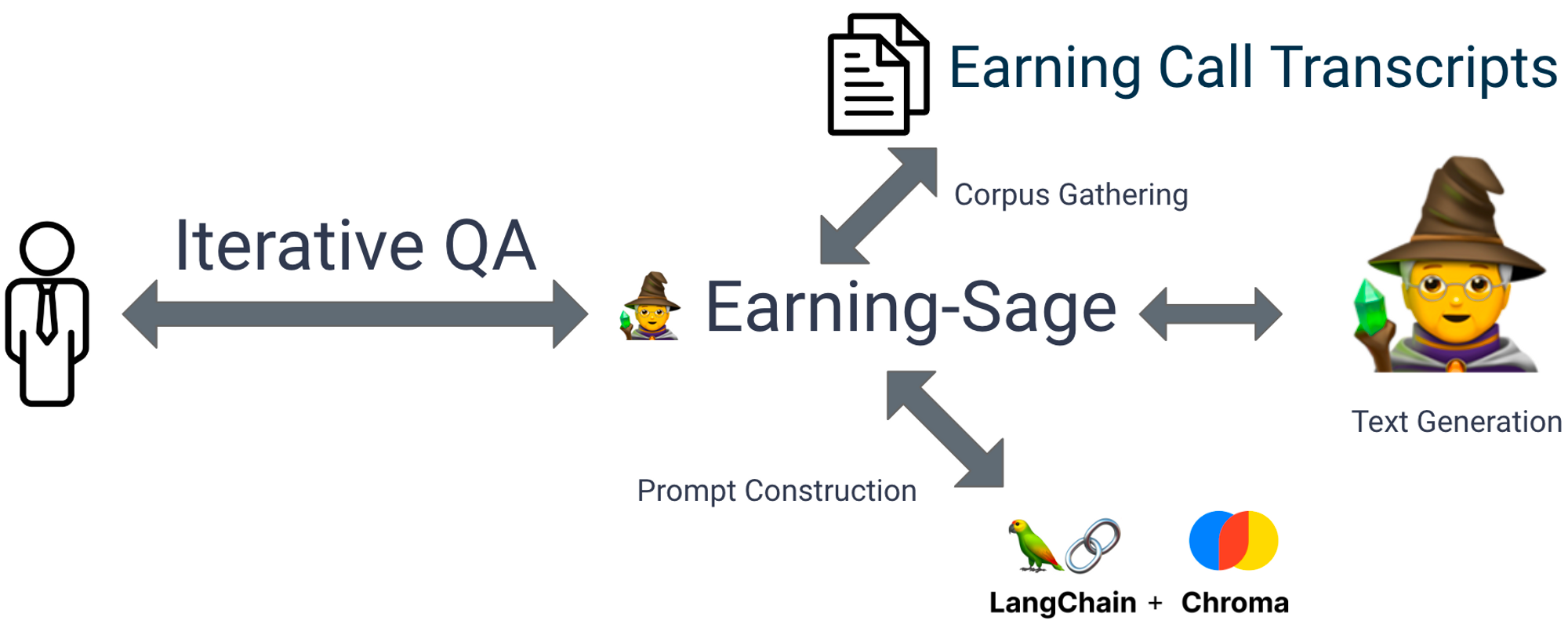
Here are few query result from the question list
- What's covered in this earning call?
- What is the potential for further growth in the number of Apple devices per iPhone user?
- What is the Apple’s strategy over AI?
- What are the feedbacks on Apply Pay Later?
Again, the only thing changed in my code is the OPENAI_API_BASE and everything works from there. By leveraging LangSmith, I get to compare the result more efficiently and share them to people who are interested in looking at it as demonstrated in this post multiple times.
Conclusion
In conclusion, the integration of data and LLM techniques, such as data augmentation and fine-tuning, stands as a pivotal milestone in the development of AI applications. By combining vast and diverse datasets with the power of LLM, we unlock unprecedented potential, enabling AI systems to generate more accurate, context-aware, and coherent outputs. The synergy between data and LLM not only enhances the overall performance of AI applications but also opens up new avenues for innovation and discovery.
As we continue to refine and expand our understanding of this dynamic relationship, we embark upon a journey where the fusion of data-driven insights and advanced language models redefines what is possible, propelling us into an era of AI excellence and transforming the way we interact with technology. The future awaits, as we stride confidently toward a horizon where AI transcends expectations and becomes an indispensable asset in our quest for progress.
And for the tools mentioned above, both LangSmith and LeptonAI are still under closed beta, but feel free to sign up on the waitlist and give it a try. Feel free to shoot me an email at uz@lepton.ai, I would love to hear from you on your thoughts!