Editor’s Note: This blog post was written in collaboration with the Neon team (Raouf Chebri in particular). The vectorstore space is on fire, and we’re excited to highlight new implementations and options. We’re also really excited by the detailed analysis done here, bringing some solid stats and insights to a novel space.
We’re very excited to announce Neon’s collaboration with LangChain to release the pg_embedding extension and PGEmbedding integration in LangChain for vector similarity search in Postgres.
But wait. Aren’t they already two other vector stores in LangChain using Postgres and PGVector? Why did the Neon team add another?
The short answer is: the Neon team built and added it for faster execution time and scalable LLM applications.
PGVector is great, it does exact similarity search by default, which results in 100% accuracy (recall). At scale, however, exact search is costly. Neon found that you can use PGVector with the IVFFlat index to improve query execution time, but that often comes at the cost of accuracy, which increases the chance of hallucination.
The Neon team carried out benchmark tests to compare the performance of pgvector and PGEmbedding, and they found out that PGEmbedding performs 20x faster for 99% accuracy.
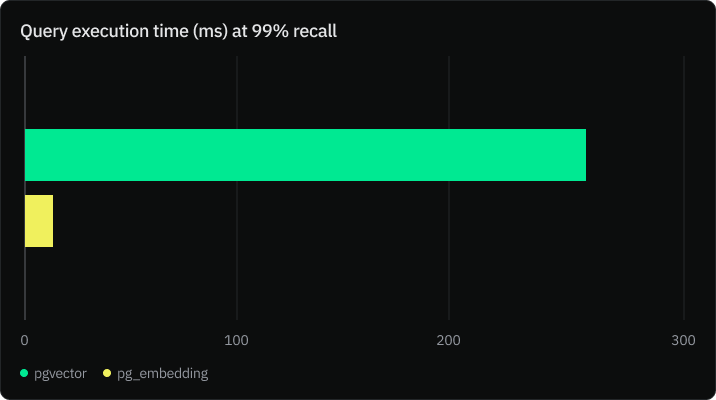
Read the full article to learn more about the benchmark here.
Why is PGEmbedding faster?
The PGEmbedding integration uses the Hierarchical Navigable Small World (HNSW) index graph-based approach to indexing high-dimensional data. It constructs a hierarchy of graphs, where each layer is a subset of the previous one, which results in a time complexity of O(log(rows)). Search with IVFFlat optimal parameters, however, often has a time complexity of O(sqrt(rows)).
How to get started with PGEmbedding
- The first step is to login to your Neon account and create a project:
npx neonctl authThe command above will direct you to the sign-up if you do not already have a Neon account.
Once logged in, create a project using the following command:
npx neonctl projects createExpected output:
┌─────────────────┬─────────────────┬───────────────┬──────────────────────┐
│ Id │ Name │ Region Id │ Created At │
├─────────────────┼─────────────────┼───────────────┼──────────────────────┤
│ dawn-sun-749604 │ dawn-sun-749604 │ aws-us-east-2 │ 2023-07-11T20:55:32Z │
└─────────────────┴─────────────────┴───────────────┴──────────────────────┘
┌───────────────────────────────────────────────────────────────────────────────────────┐
│ Connection Uri │
├───────────────────────────────────────────────────────────────────────────────────────┤
│ postgres://<user>:<password>@ep-lingering-moon-792025.us-east-2.aws.neon.tech/neondb │
└───────────────────────────────────────────────────────────────────────────────────────┘2. Follow the instructions in the documentation to install LangChain if you haven’t done so already.
3. The code below initializes the PGEmbedding vector store, and executes a similarity analysis
import os
from typing import List, Tuple
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import PGEmbedding
from langchain.document_loaders import TextLoader
from langchain.docstore.document import Document
loader = TextLoader('state_of_the_union.txt')
raw_docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(raw_docs)
embeddings = OpenAIEmbeddings()
CONNECTION_STRING = os.environ["DATABASE_URL"]
# Initialize the vectorstore, create tables and store embeddings and
# metadata.
db = PGEmbedding.from_documents(
embedding=embeddings,
documents=docs,
collection_name="state_of_the_union",
connection_string=CONNECTION_STRING,
)
# Create the index using HNSW. This step is optional. By default the
# vectorstore uses exact search.
db.create_hnsw_index(max_elements=10000, dims=1536, m=8, ef_construction =16, ef_search=16)
# Execute the similarity search and return documents
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query)
print('query done')
print("Results:")
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
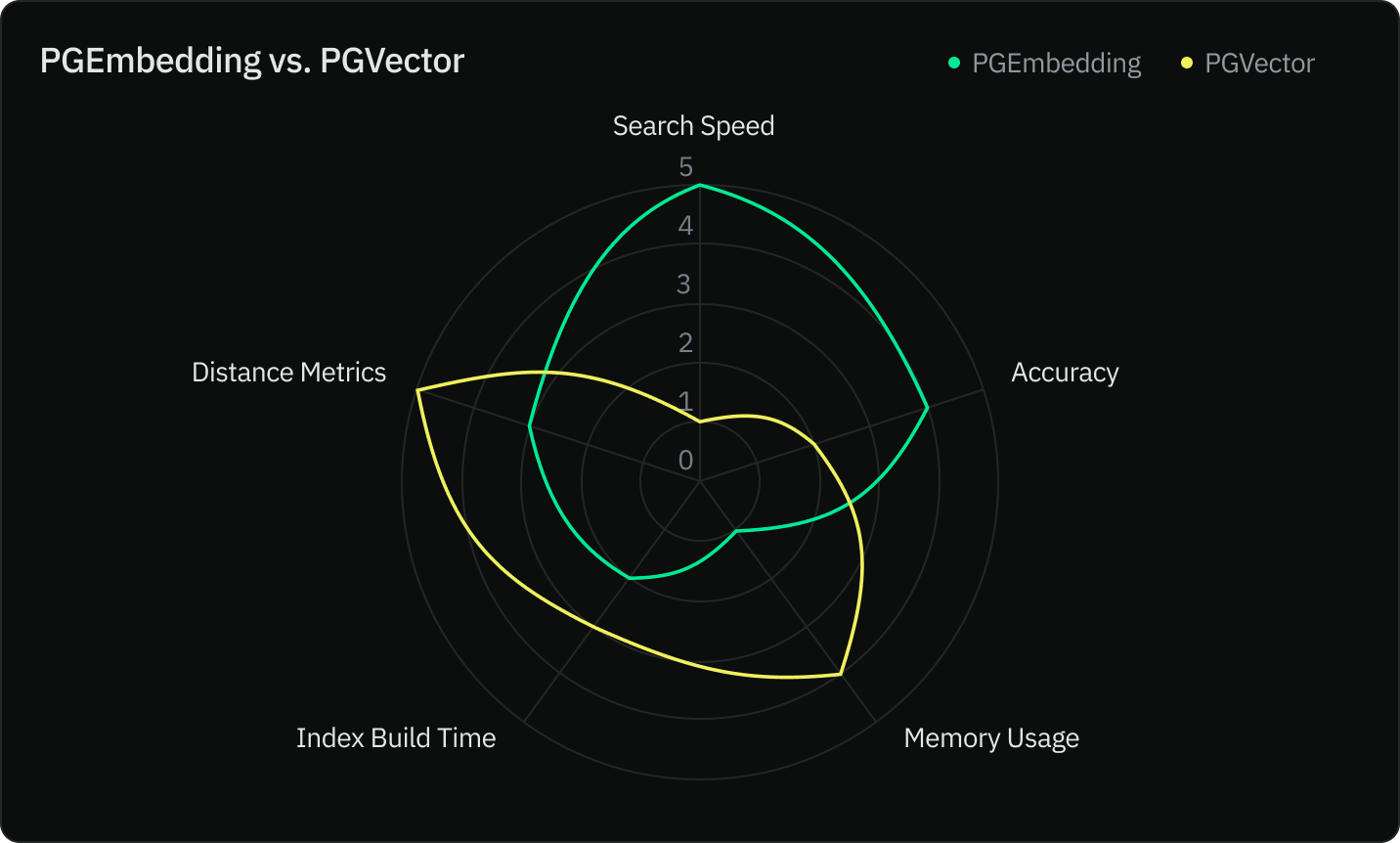
print("-" * 80)PGEmbedding vs PGVector: Which vector store should you pick?
The Neon team compared both indexes using five criteria:
- Search speed
- Accuracy
- Memory usage
- Index construction speed
- Distance metrics
Conclusion
With the introduction of the PGEmbedding integration, you now have a powerful new tool at your disposal for your LLM apps. PGVector remains a viable choice for applications with stringent memory constraints but at the expense of recall.
Ultimately, the choice between PGEmbedding and other vector stores should be informed by the specific demands of your application. We encourage you to experiment with both approaches to find the one that best meets your needs.
We are excited to see what you are going to build with PGEmbedding and look forward to your feedback!
Happy coding!