[Editor's Note]: This is the second of hopefully many guest posts. We intend to highlight novel applications building on top of LangChain. If you are interested in working with us on such a post, please reach out to harrison@langchain.dev.
Authors: Parth Asawa (pgasawa@), Ayushi Batwara (ayushi.batwara@), Jason Ding (jasonding@), Arvind Rajaraman (arvind.rajaraman@) [@berkeley.edu]
The Problem
Has your browser ever looked like this?

There’s probably been a time when you’ve had too many tabs to count open across different windows. Why? Because we’re never working on just one thing at once. As students, you may have tabs open for different courses, different projects, activities, etc., and as a developer, you may have different projects, planning tabs, etc. You get the idea.
You may have attempted a solution, though — tab groups:

But what do these tab groups accomplish? Do they get rid of the clutter they sought to get rid of? No. Instead, we end up opening more and more tabs in the hope that one day we will use that one paragraph from that one long-lost tab. The more open tabs, the harder context switching becomes; it’s all just clutter.
Knowledge grows stale, too — it’s hard to keep track of the information across all the tabs constantly, and in most cases, we forget it. There’s no concept of knowledge centralization.
Mission
Given this ubiquitous problem that people face in the current browsing experience, something that has not seen any radical innovation or change in quite a while, we set out to disrupt that with Origin.
We’re all students at UC Berkeley currently pursuing dual degrees in EECS & Business Administration through the Management, Entrepreneurship, and Technology (M.E.T.) Program.
This project was an idea we built out over 36 hours at Stanford’s annual hackathon, TreeHacks.
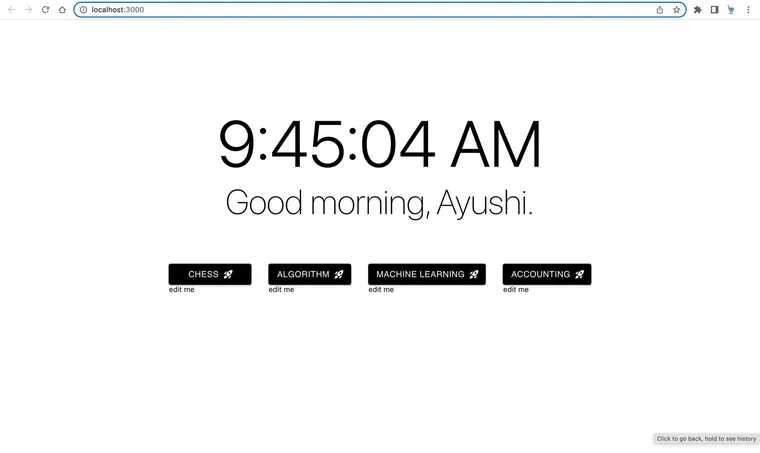
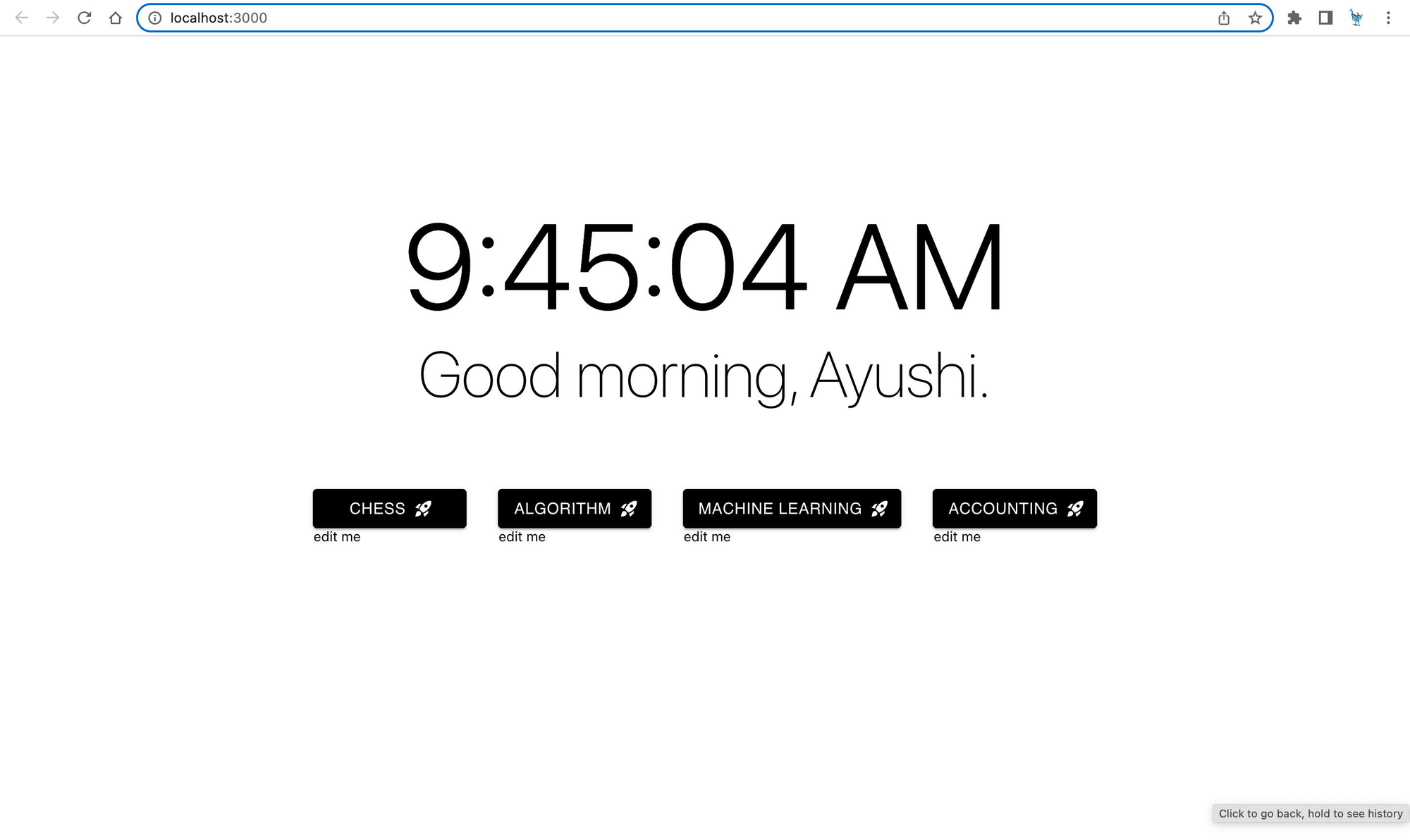
Origin is an app to take in your existing browser history and organizes it into context-aware workspaces with automatically generated summaries, which then offer workspace-specific semantic search, recommendation systems, and chatbots.
We take in your browsing history, create embeddings, and automatically run a clustering algorithm to learn workspaces. We enable semantic search to find different URLs within workspaces easily, so you never have to be scared of closing a tab; then, we scrape the websites to create summaries and use a highly specific ChatBot per workspace. This allows for knowledge centralization, ease of access to existing knowledge, and persistence in knowledge — it’ll be there even if you close a tab.
An example V0 landing page with some learned workspaces:
Tech Dive
In this blog post, we’ll primarily focus on how LangChain fit into our project. As an aside, we rely on some traditional ML and statistical techniques like K-Means, collaborative filtering, off the shelf HF embeddings, and more to incorporate some of the other features like clustering, semantic search, recommendation systems, etc.
We incorporated LangChain into two key facets of this MVP browser experience that occurs when you launch a workspace.
Summarization
The first was summarization. We wanted an effective way to remind users where they left off in a workspace. Using BeautifulSoup, we developed a web scraper to parse through recently visited websites. From this information, we wanted a way to generate an effective summary and relied on LangChain’s ‘map_reduce’ summarization chain to efficiently summarize large amounts of text using OpenAI embeddings.

Chatbot
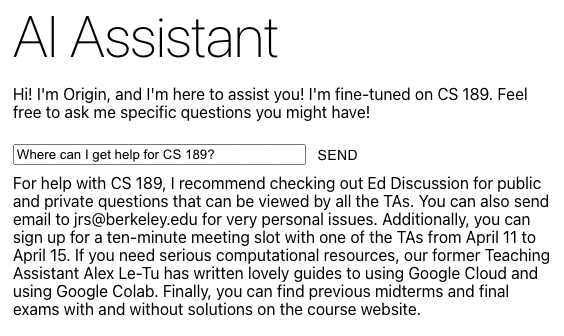
The second was the ability to ‘chat your browser.’ Users have knowledge spread across hundreds of tabs that they rarely revisit and spend the time to parse through. But if the user wants an easy way to interact with their knowledge, it doesn’t exist. A chatbot with access to all the information in those browsers does, though. Using the same web scraper, we followed the model set by LangChain’s Chat Your Data example and broke the text down into smaller chunks that were then embedded and stored in a vectorstore. This vectorstore is then used at serve time as a part of the ChatVectorDBChain to provide context to our chatbot based on OpenAI models and generate highly specific responses to the user’s workspace context.
Conclusion and Future Direction
Despite all this fun exploration, there’s a good amount of things to think about which wouldn’t scale in the real world. As an example, compute costs with the standard GPT-3 models were expensive and likely not sustainable in the way we used them. Figuring out ways to optimize the costs of using LLMs is something we feel will be an interesting challenge tackled by any company that integrates them into their product.
Going beyond a hackathon project, thinking about this as a real product, we’d likely re-design this from the ground up and focus on getting some key technical features and processes right so that it actually provides a baseline level of value, before trying to add some of the more fancy features. Taking the summarization tool as an example, while this was cool in the moment, it’s hard to actually extract a summary of a workspace that’d be useful to a user without a lot more selective filtering and engineering. We’re excited to spend some time now thinking about these more challenging eng and design problems - LangChain is a tool that’ll definitely be used!
Thanks for reading! Reach out to us on LinkedIn/Twitter/Email (@berkeley.edu) — we’d love to hear from you!