Key Links
Context
LLMs are unlocking a new era of generative AI applications, becoming the kernel process of a new kind of operating system. Just as modern computers have RAM and file access, LLMs have a context window that can be loaded with information retrieved from external data sources, such as databases or vectorstores.
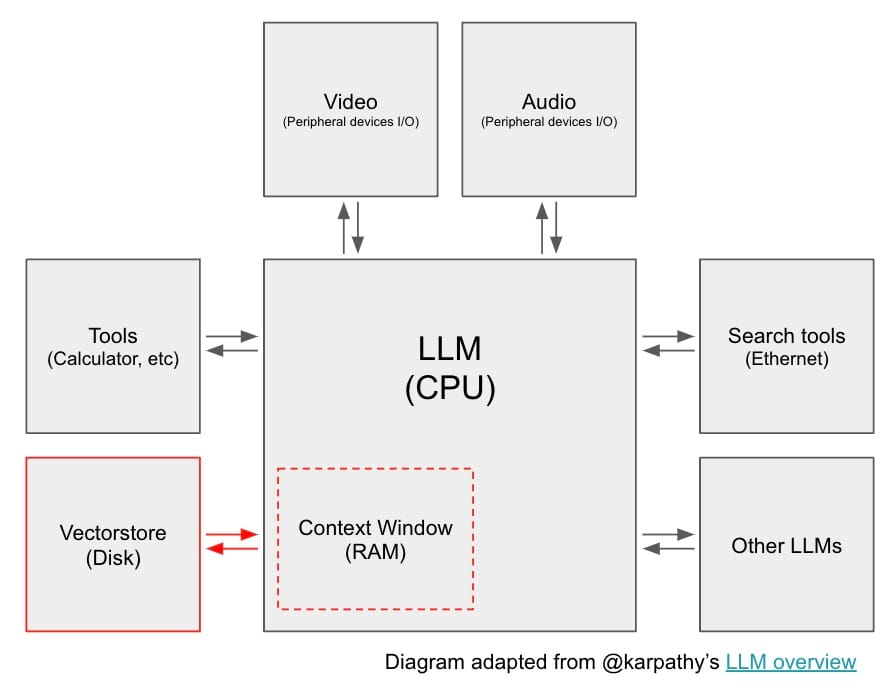
Retrieved information can be loaded into the context window and used in LLM output generation, a process called retrieval augmented generation (RAG). RAG is a central concept in LLM app development because it can reduce hallucinations by grounding output and adds context that is not present the training data.
Challenges with production
With these points in mind, vectorstores have gained considerable popularity in production RAG applications because they offer a good way to store and retrieve relevant context. In particular, semantic similarity search is commonly used to retrieve chunks of information that are relevant to a user-provided input.
A large number of RAG demos have been shared over the past months, often using tools such as Jupyter notebooks and local vectorstores. Yet, several pain points create a gap between these demos and production RAG applications. Below, we'll discuss several ways to overcome these gaps and provide both a repo and a hands-on video that builds a production RAG application from scratch.
Support for production
Pinecone Serverless
Pinecone is one of the most popular LangChain vectorstore integration partners and has been widely used in production due to its support for hosting. Yet, at least two pain points we've heard from the community include: (1) the need to provision your own Pinecone index and (2) pay a fixed monthly price for the index regardless of usage. The launch of Pinecone serverless addresses both of these challenges, providing “unlimited” index capacity via cloud object storage (ex. S3 or GCS) along with considerably reduce cost to serve (allowing users to pay for what they use).
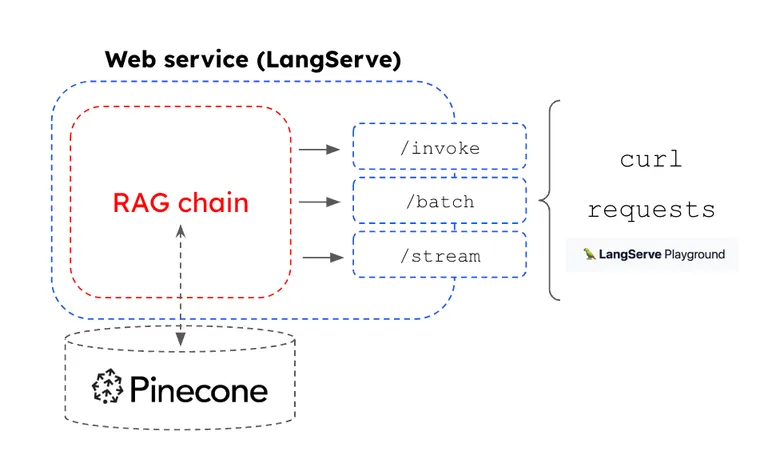
LangServe
While LangChain has become popular for rapid prototyping RAG applications, we saw an opportunity to support rapid deployment of any chain to a web service that is suitable for production. This motivated LangServe. Any chain composed using LCEL has a runnable interface with a common set of invocation methods (e.g., batch, stream). With LangServe, these methods are mapped to HTTP endpoints in of a web service, which can be managed using Hosted LangServe.
LangSmith
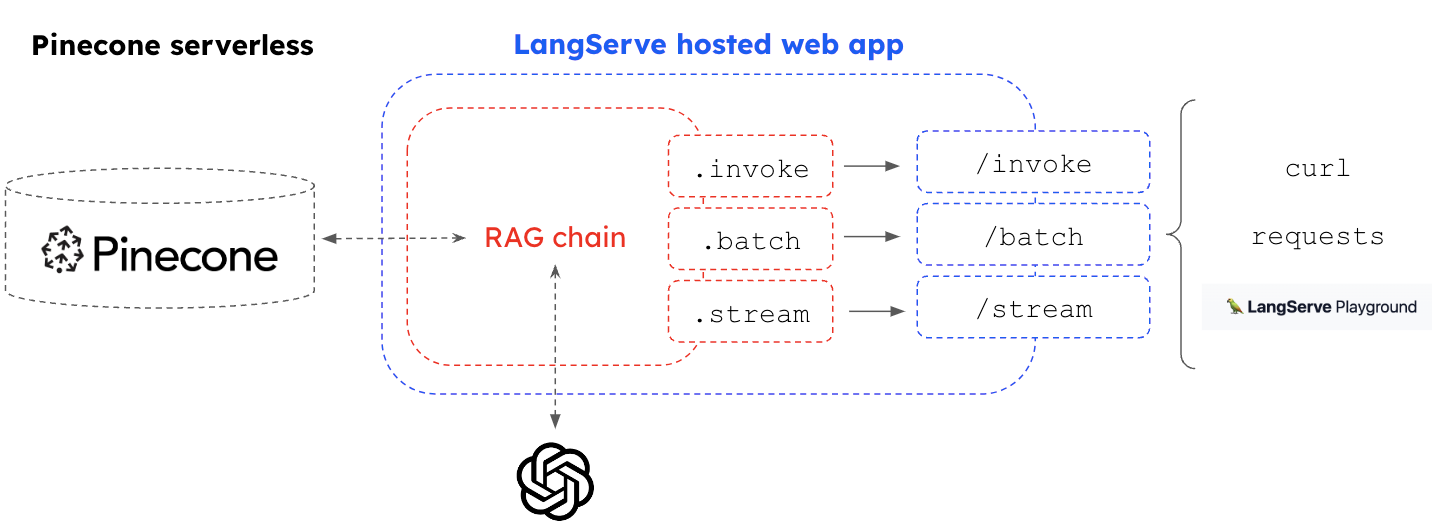
LangSmith offers a platform for LLM observability that integrates seamlessly with LangServe. We can compose a RAG chain that connects to Pinecone Serverless using LCEL, turn it into an a web service with LangServe, use Hosted LangServe deploy it, and use LangSmith to monitor the input / outputs.
Example Application
To show how all these pieces come together, we provide a template repo.
- It shows how to connect a Pinecone Serverless index to a RAG chain in LangChain, which includes Cohere embeddings for similarity search on the index as well as GPT-4 for answer synthesis based upon the retrieved chunks.
- It shows how to convert the RAG chain into a web service with Langserve. With LangServe, the chain can then be deployed using hosted LangServe.
Conclusion
We see demand for tools that bridge the gap between prototyping and production. With usage based pricing and support for unlimited scaling, Pinecone Serverless helps to address pain points with vectorstore productionization that we've seen from the community. Pinecone Serverless pairs well with LCEL, Hosted LangServe, and LangSmith to support easly deployment of RAG applications.