Context
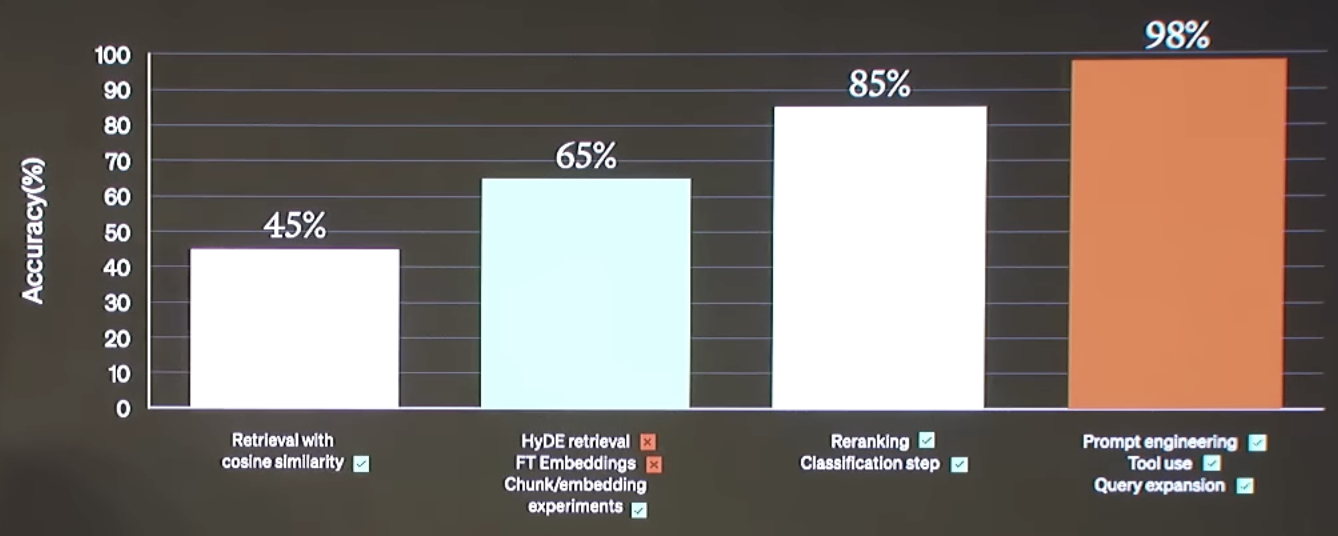
At their demo day, Open AI reported a series of RAG experiments for a customer that they worked with. While evaluation metics will depend on your specific application, it’s interesting to see what worked and what didn't for them. Below, we expand on each method mention and show how you can implement each one for yourself. The ability to understand and these methods on your application is critical: from talking to many partners and users, there is no "one-size-fits-all" solution because different problems require different retrieval techniques.
How these fit into the RAG stack
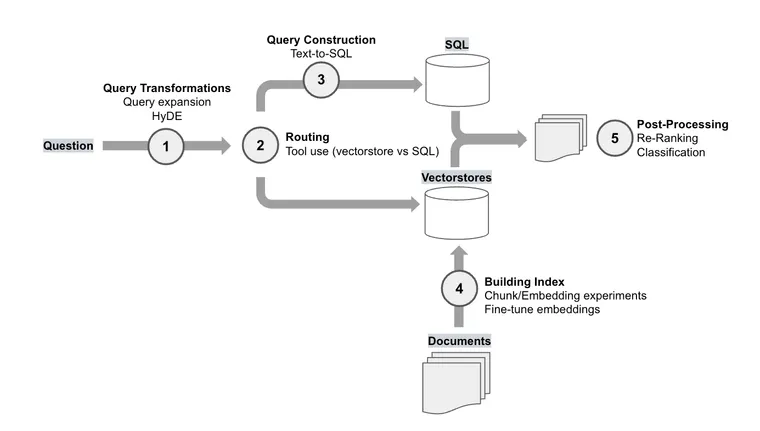
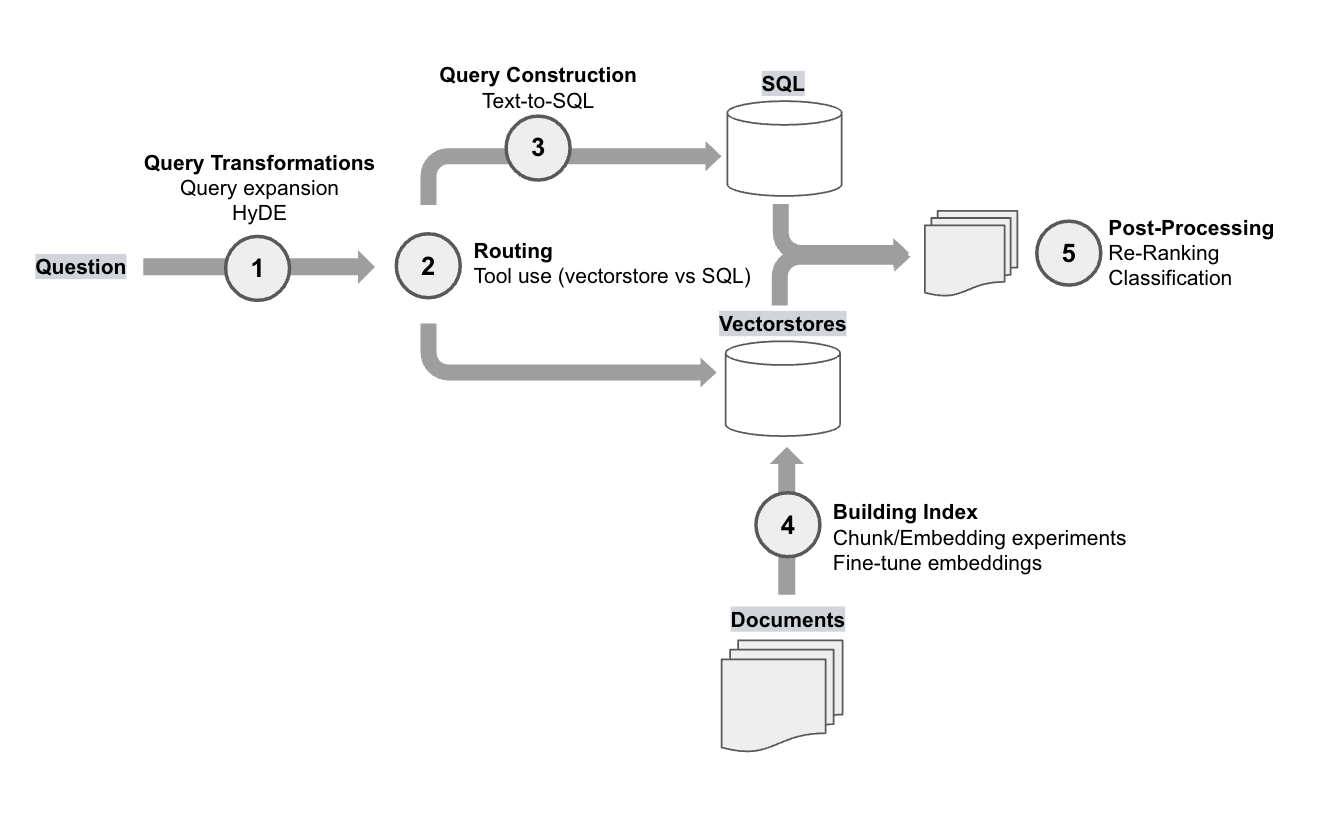
First, we can bin these methods into a few RAG categories. Here is a diagram that shows each RAG experiment in its category and places them in the RAG stack:
Baseline
Distance-based vector database retrieval embeds (represents) queries in high-dimensional space and finds similar embedded documents based on "distance". The base-case retrieval method used in the OpenAI study mentioned cosine similarity. LangChain has over 60 vectorstore integrations, many of which allow for configuration distance functions used in similarity search. Useful blog posts on the various distance metrics can be found from Weaviate and Pinecone.
Query Transformations
However, retrieval may produce different results due to subtle changes in query wording or if the embeddings do not capture the semantics of the data well. Query transformations are a set of approaches focused on modifying the user input in order to improve retrieval. See our recent blog on the topic here.
OpenAI reported two methods, which you can try:
- Query expansion: LangChain’s Multi-query retriever achieves query expansion using an LLM to generate multiple queries from different perspectives for a given user input query. For each query, it retrieves a set of relevant documents and takes the unique union across all queries.
- HyDE: LangChain’s HyDE (Hypothetical Document Embeddings) retriever generates hypothetical documents for an incoming query, embeds them, and uses them in retrieval (see paper). The idea is that these simulated documents may have more similarity to the desired source documents than the question.
Other ideas to consider:
- Step back prompting: For reasoning tasks, this paper shows that a step-back question can be used to ground an answer synthesis in higher-level concepts or principles. For example, a question about physics can be abstracted into a question and answer about the physical principles behind the user query. The final answer can be derived from the input question as well as the step-back answer. The this blog post and the LangChain implementation to learn more.
- Rewrite-Retrieve-Read: This paper re-writes user questions in order to improve retrieval. See the LangChain implementation to learn more.
Routing
When querying across multiple datastores, routing questions to the appropriate source become critical. The OpenAI presentation reported that they needed to route question between two vectorstores and single SQL database. LangChain has support for routing using an LLM to gate user-input into a set of defined sub-chains, which - as in this case - could be different vectorstores.
Query Construction
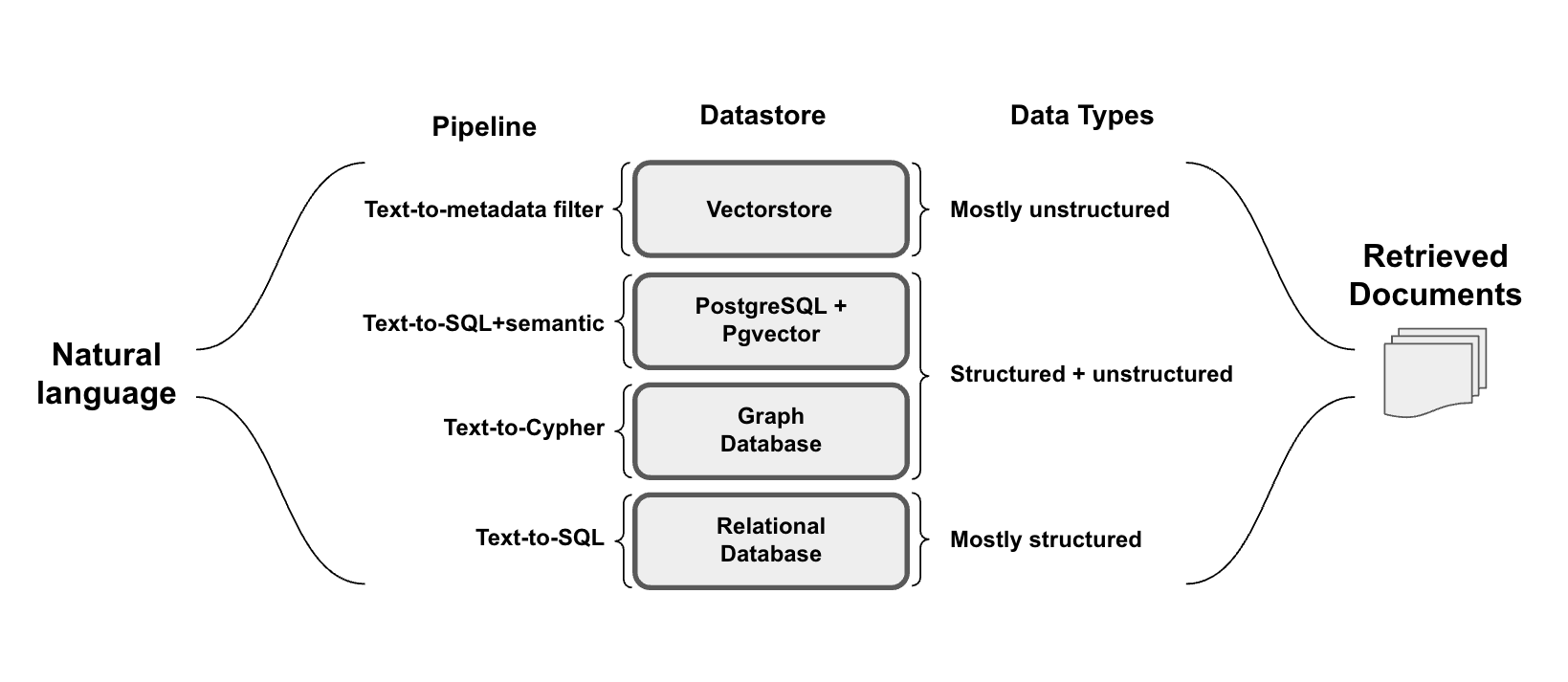
Because one of the datasources mentioned in the OpenAI study is a relational (SQL) database, valid SQL needed to be generated from the user input in order to extract the necessary information. LangChain has support for text-to-sql, which is reviewed in depth in our recent recent blog focused on query construction.
Other ideas to consider:
- Text-to-metadata filter for vectorstores
- Text-to-Cypher for graph databases
- Text-to-SQL+semantic for semi-structured data in Postgres with Pgvector
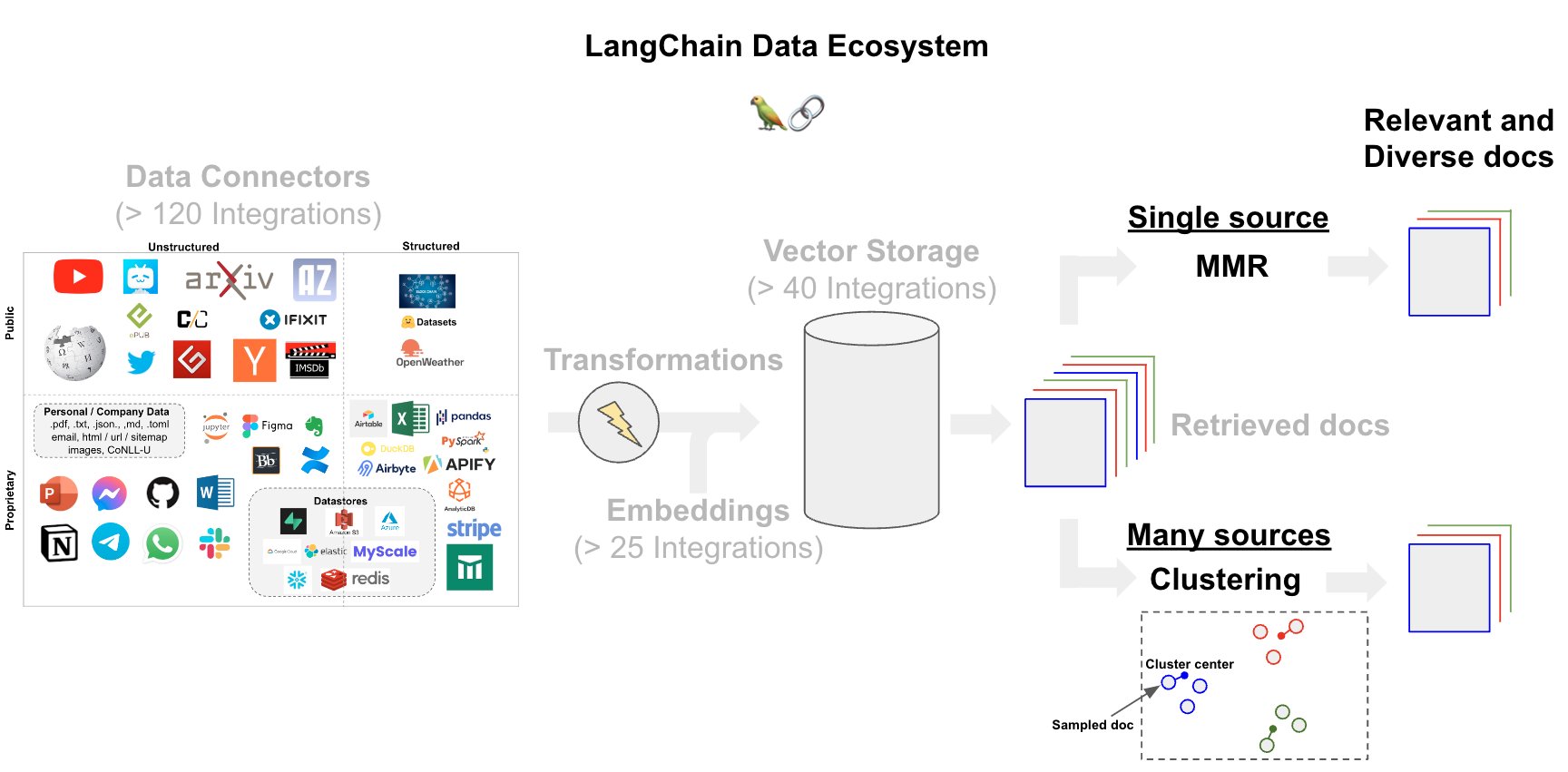
Building the Index
OpenAI reported an notable boost in performance simply from experimenting with the chunk size during document embedding. Because this is a central step in index building, we have an open source Streamlit app where you can test chunk sizes.
While they did not report a considerable boost in performance from embedding fine-tuning, favorable results have been reported. While OpenAI notes that this is probably not advised as "low-hanging-fruit", we have shared guides for fine-tuning and there are some very good tutorials from HuggingFace that go deeper on this.
Post-Processing
Processing documents following retrieval, but prior to LLM ingestion, is an important strategy for many applications. We can use post-processing to enforce diversity or recency among our retrieved documents, which can be especially important when we are pooling documents from multiple sources.
OpenAI reported two methods:
- Re-rank: LangChain’s integration with the Cohere ReRank endpoint is one approach, which can be used for document compression (reduce redundancy) in cases where we are retrieving a large number of documents. Relatedly, RAG-fusion uses reciprocal rank fusion (see blog and implementation) to ReRank documents returned from a retriever similar to multi-query (discussed above).
- Classification: OpenAI classified each retrieved document based upon its content and then chose a different prompt depending on the classification. This marries two ideas: LangChain supports tagging of text (e.g., using function calling to enforce the output schema) for classification. As mentioned above, logical routing can also be used to route based on a tag (or include the process of semantic tagging in the logical routing chain itself).
Other ideas to consider:
- MMR: To balance between relevance and diversity, many vectorstores offer max-marginal-relevance search (see blog post here).
- Clustering: Some approaches have used clustering of embedded documents with sampling, which may be helpful in cases where we are consolidating documents across a wide range sources.
Conclusion
It's instructive to see what OpenAI has tried on the topic of RAG. The approaches can be reproduced in your own hands as shown above: trying different methods is crucial because application performance can vary widely on the RAG setup.
However, the OpenAI results also show that evaluation is critically important to avoid wasted time and effort on approaches that yield little or no benefit. For RAG evaluation, LangSmith offers a great deal of support: for example, here is a cookbook using LangSmith to evaluate several advanced RAG chains.