Context
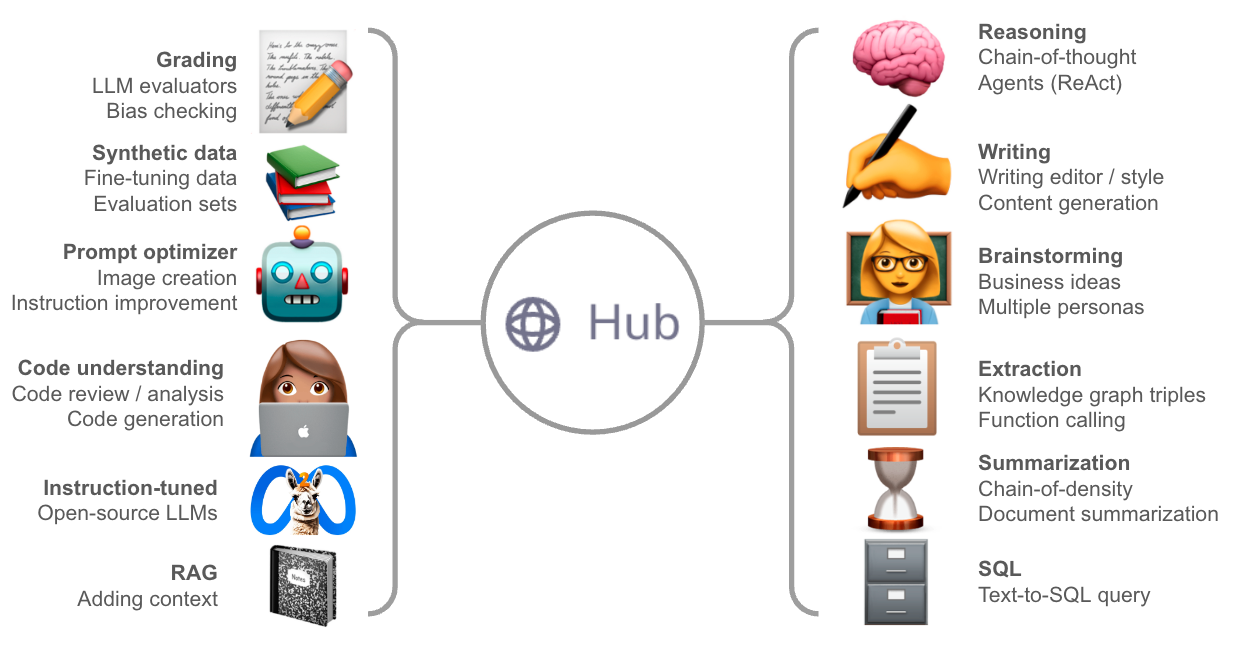
Prompt Engineering can steer LLM behavior without updating the model weights. A variety of prompts for different uses-cases have emerged (e.g., see @dair_ai’s prompt engineering guide and this excellent review from Lilian Weng). As the number of LLMs and different use-cases expand, there is increasing need for prompt management to support discoverability, sharing, workshopping, and debugging prompts. We launched the LangChain Hub over a month ago to support these needs, serving as a home for both browsing community prompts and managing your own. Below we provide an overview of the major themes in prompting that we’ve seen since launch and highlight interesting examples.
Reasoning
Chain-of-thought reasoning encourages the LLM to spread its “thinking” out across many tokens: it conditions the LLM to show its work using a simple statement e.g., Let's think step by step. This has found broad appeal because it improves many reasoning tasks by a large margin and is easy to implement. More sophisticated approaches (e.g., Tree-of-thought) are also worth consideration, but the benefit relative to the overhead (tokens) should be evaluated.
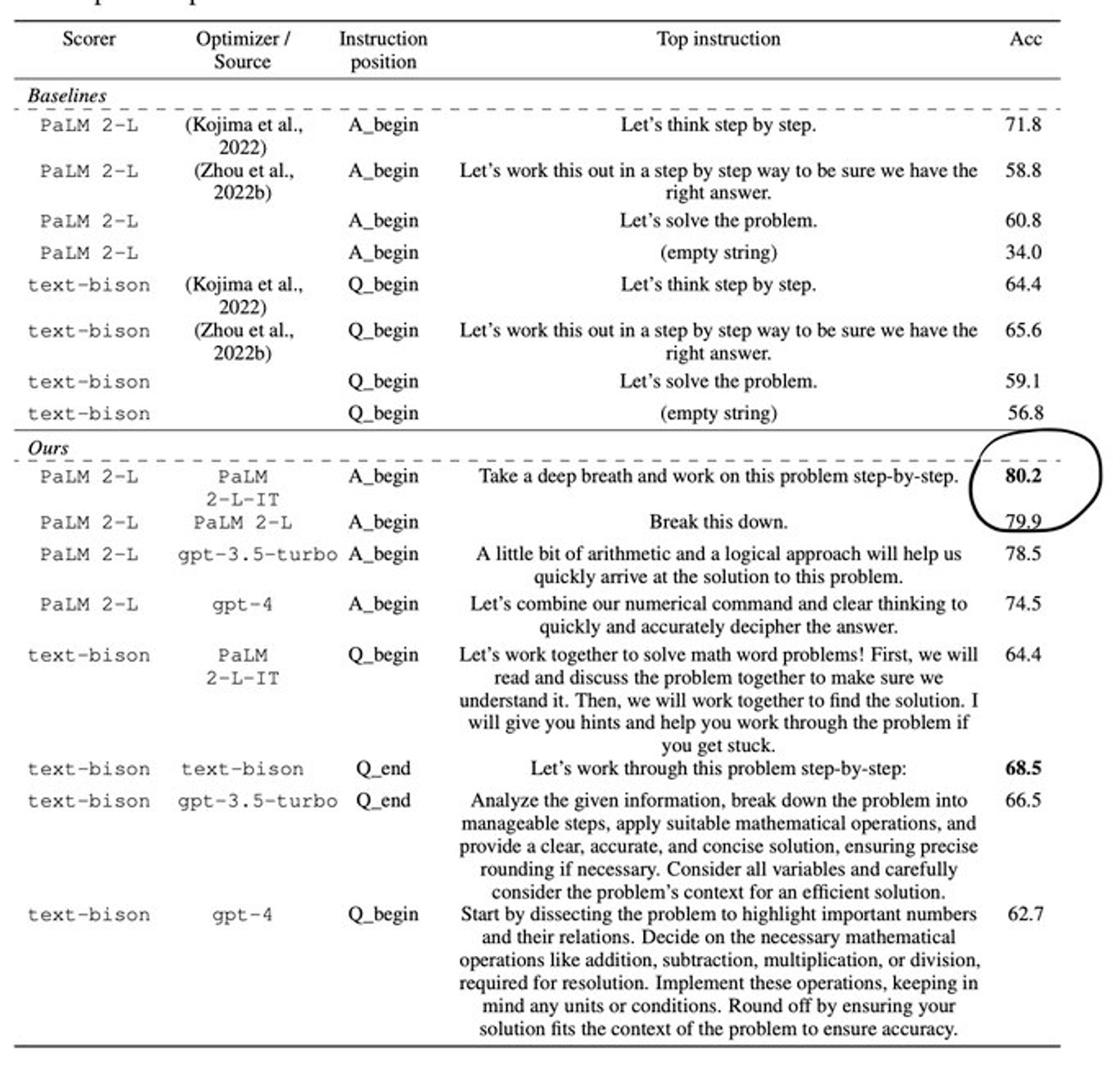
Deepmind recently used LLMs to optimize prompts, and converged to Take a deep breath and work on this problem step-by-step as the best performing optimization. Going forward, this points to some interesting potential for translation modules between human instruction and LLM-optimized prompts.
Reasoning prompts as shown above can be appended as simple instructions to many tasks and have become particularly important for agents. For example, ReAct agents combine tool use with reasoning in an interleaved manner. Agent prompts can encode multi-step reasoning in different ways, but often with the goal of updating action plans given observations. See Lilian Weng's excellent post on agents for a full review of the various approaches on agent design and prompting.
Examples
- https://smith.langchain.com/hub/hwchase17/react
- https://smith.langchain.com/hub/shoggoth13/react-chat-agent
- https://smith.langchain.com/hub/jacob/langchain-tsdoc-research-agent
Writing
Prompts to improve writing have widespread appeal given the impressive displays of creativity from LLMs. @mattshumer_’s popular GPT4 prompts provide ways to improve writing clarity or customize the style of LLM-generated text. Leveraging LLM's capacity for language translation is another good application for writing.
Examples
- https://smith.langchain.com/hub/rlm/matt-shumer-writing
- https://smith.langchain.com/hub/rlm/matt-shumer-writing-style
- https://smith.langchain.com/hub/agola11/translator
There's also been a proliferation of prompts for producing diverse content (e.g., onboarding emails, blog posts, Tweet threads, learning materials for education).
Examples
- https://smith.langchain.com/hub/gitmaxd/onboard-email
- https://smith.langchain.com/hub/hardkothari/blog-generator
- https://smith.langchain.com/hub/gregkamradt/test-question-making
- https://smith.langchain.com/hub/bradshimmin/favorite_prompts
- https://smith.langchain.com/hub/hardkothari/tweet-from-text
- https://smith.langchain.com/hub/julia/podcaster-tweet-thread
SQL
Because enterprise data is often captures in SQL databases, there is great interest in using LLMs as a natural language interface for SQL (see our blog post). A number of papers have reported that LLMs can generate SQL given some specific information about the table, including a CREATE TABLE description for each table followed by three example rows in a SELECT statement. LangChain has numerous tools for querying SQL databases (see our use case guide and cookbook).
Examples
Brainstorming
Many people have had instructive and / or entertaining conversations with LLMs. LLMs have proven broadly useful for brainstorming: one trick is to create multiple user personas that work through an idea collectively, as shown by @mattshumer_ business plan ideation prompt. The principle can be adapted broadly. As an example, BIDARA (Bio-inspired Design and Research Assistant) is a GPT-4 chatbot instructed to help scientists and engineers understand, learn from, and emulate the strategies used by living things for new designs and technologies.
Examples
- https://smith.langchain.com/hub/hwchase17/matt-shumer-validate-business-idea
- https://smith.langchain.com/hub/bruffridge/bidara
Extraction
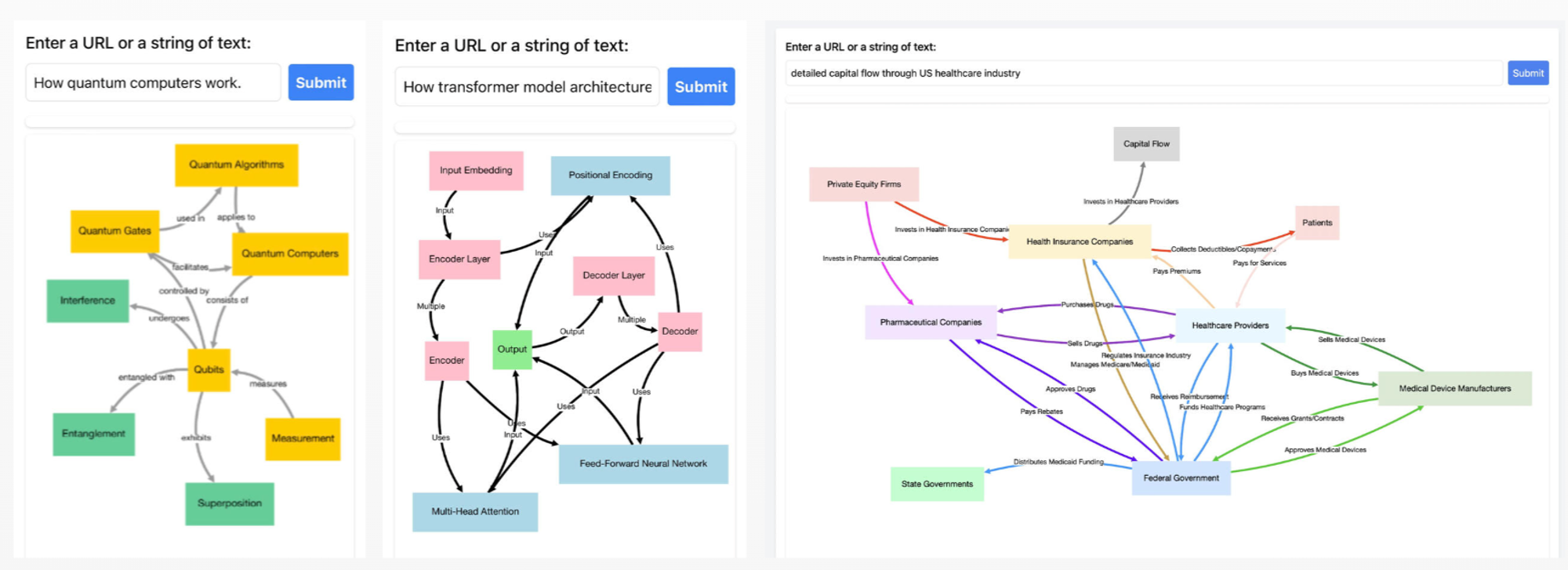
LLMs can be powerful tools for extracting text in particular formats, often aided by function calling. This is a rich area with frameworks developed to support it, such as @jxnlco’s Instructor (see their guide on prompt engineering). We've also seen prompts designed for specific extraction tasks, such as knowledge graph triple extraction (as shown by tools like Instagraph or the text-to-graph playground).
Examples
- https://smith.langchain.com/hub/langchain/knowledge-triple-extractor
- https://smith.langchain.com/hub/homanp/superagent
RAG
Retrieval augmented generation (RAG) is a popular LLM application: it passes relevant context to the LLM via prompt. RAG has particular promise for factual recall because it marries the reasoning capability of LLMs with the content of external data sources, which is particularly powerful for enterprise data.

Examples
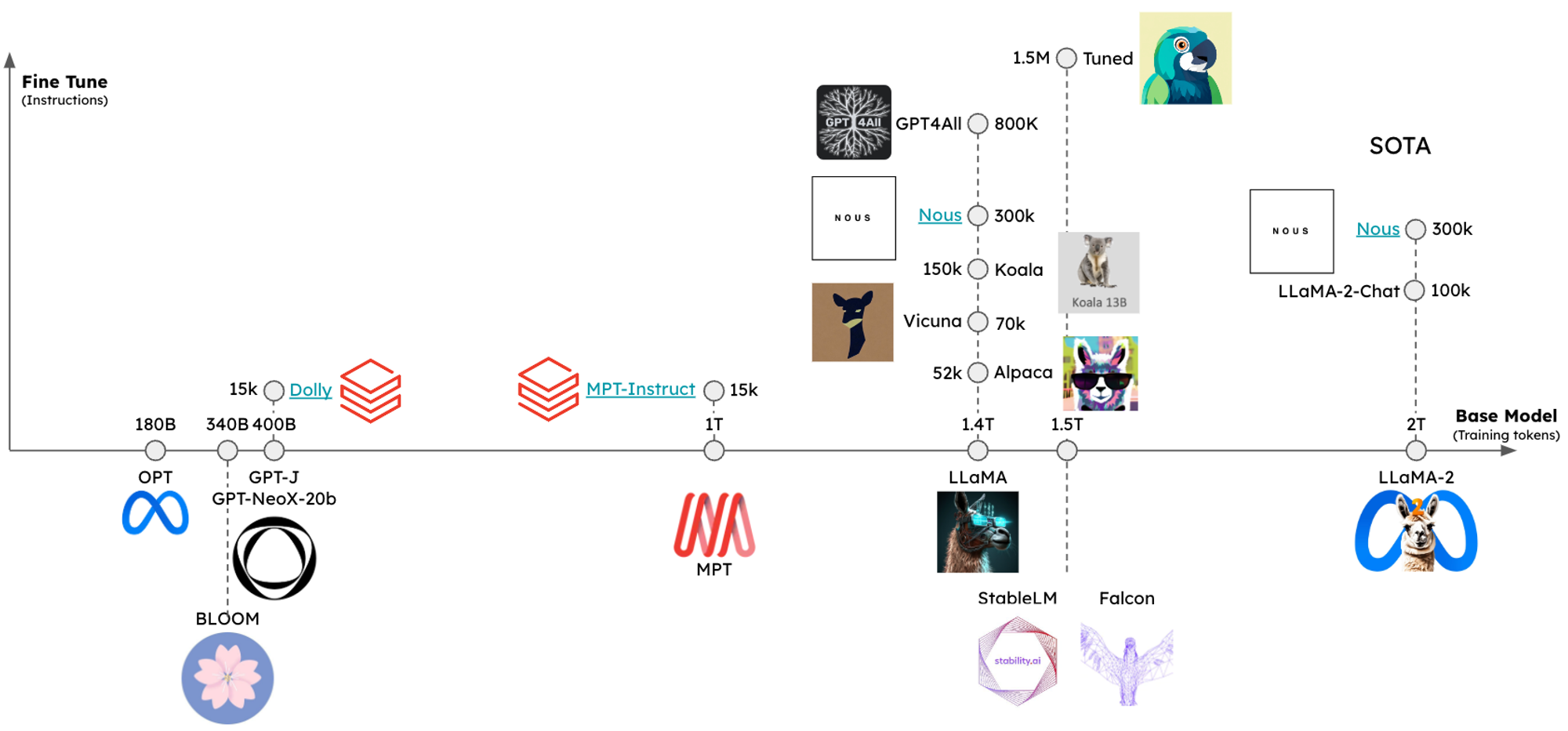
Instruction-tuned LLMs
The landscape of open source instruction-tuned LLMs has exploded over the past year. With this has come a variety of popular LLMs that each have specific prompt instructions (e.g., see instruction for LLaMA2 and Mistral). Popular tasks such as retrieval augmented generation (RAG) can benefit from LLM-specific-prompts.
Examples
- https://smith.langchain.com/hub/rlm/rag-prompt-llama
- https://smith.langchain.com/hub/rlm/rag-prompt-mistral
LLM Graders
Using LLMs as graders is a powerful idea that has been broadly showcased in OpenAI cookbooks and open source projects: the central idea is to utilize the discrimination of an LLM to rank or grade a response relative to a ground truth answer (or for consistently relative to reference materials such as retrieved context). Much of the work on LangSmith has focused on evaluation support.
Examples
- https://smith.langchain.com/hub/simonp/model-evaluator
- https://smith.langchain.com/hub/wfh/automated-feedback-example
- https://smith.langchain.com/hub/smithing-gold/assumption-checker
Synthetic Data generation
Fine-tuning LLMs is one of the primary ways (along with RAG) to steer LLM behavior. Yet, gathering training data for fine-tuning is a challenge. Considerable work has focused on using LLMs to generate synthetic datasets.
Examples
- https://smith.langchain.com/hub/homanp/question-answer-pair
- https://smith.langchain.com/hub/gitmaxd/synthetic-training-data
Prompt Optimization
The Deepmind work showing that LLMs can optimize prompts offers the broad potential for translation modules between human instruction and LLM-optimized prompts. We’ve seen a number of interesting prompts along these lines; one good example is for Midjourney, which has incredible creative potential to unlock through prompting and parameter flags. For a general input idea (Freddie Mercury performing at the 2023 San Francisco Pride Parade hyper realistic), it can produce a series of N prompts that embellish the idea, as shown below:
Freddie Mercury electrifying the San Francisco Pride Parade stage, shining in a gleaming golden outfit, iconic microphone stand in hand, evoking the hyper-realistic style of Caravaggio, vivid and dynamic --ar 16:9 --q 2)

Examples
- https://smith.langchain.com/hub/hardkothari/prompt-maker
- https://smith.langchain.com/hub/aemonk/midjourney_prompt_generator
Code Understanding and Generation
Code analysis is one of the most popular LLM use-cases, as demonstrated by the popularity of GitHub co-pilot and Code Interpreter as well as fine-tuned LLMs (Code LLaMA). We've seen a number of prompts related to this theme:
Examples
- https://smith.langchain.com/hub/chuxij/open-interpreter-system
- https://smith.langchain.com/hub/homanp/github-code-reviews
- https://smith.langchain.com/hub/muhsinbashir/text-to-streamlit-webap
Summarization
Summarization of content is a powerful LLM use-case. Longer context LLMs, such as Anthropic Claude2, can absorb > 70 pages for direct summarization. Prompting techniques like chain of density offer a complimentary approach, resulting in dense yet human-preferable summaries.
Examples
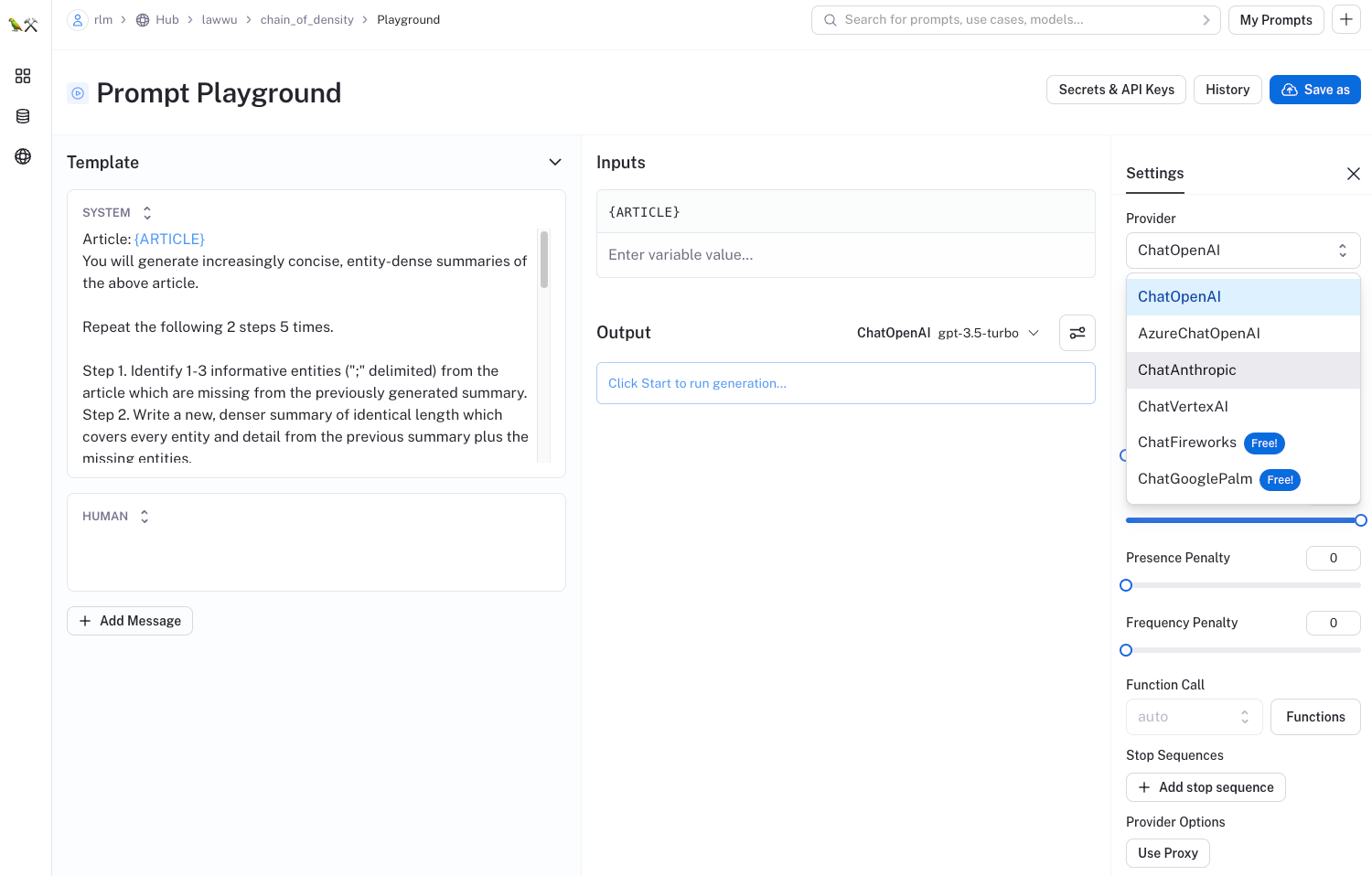
- https://smith.langchain.com/hub/lawwu/chain_of_density
- https://smith.langchain.com/hub/hwchase17/anthropic-paper-qa
- https://smith.langchain.com/hub/muhsinbashir/youtube-transcript-to-article
- https://smith.langchain.com/hub/hwchase17/anthropic-chain-of-density
In addition, summarization can be applied to diverse content types like chat conversations (e.g., compress the content to pass as context into chat LLM memory) or domain specific data (financial table summarization)
Examples
- https://smith.langchain.com/hub/langchain-ai/weblangchain-search-query
- https://smith.langchain.com/hub/hwchase17/financial-table-insights
Conclusion
You can easily test any of these prompts for yourself using "Try It" button:
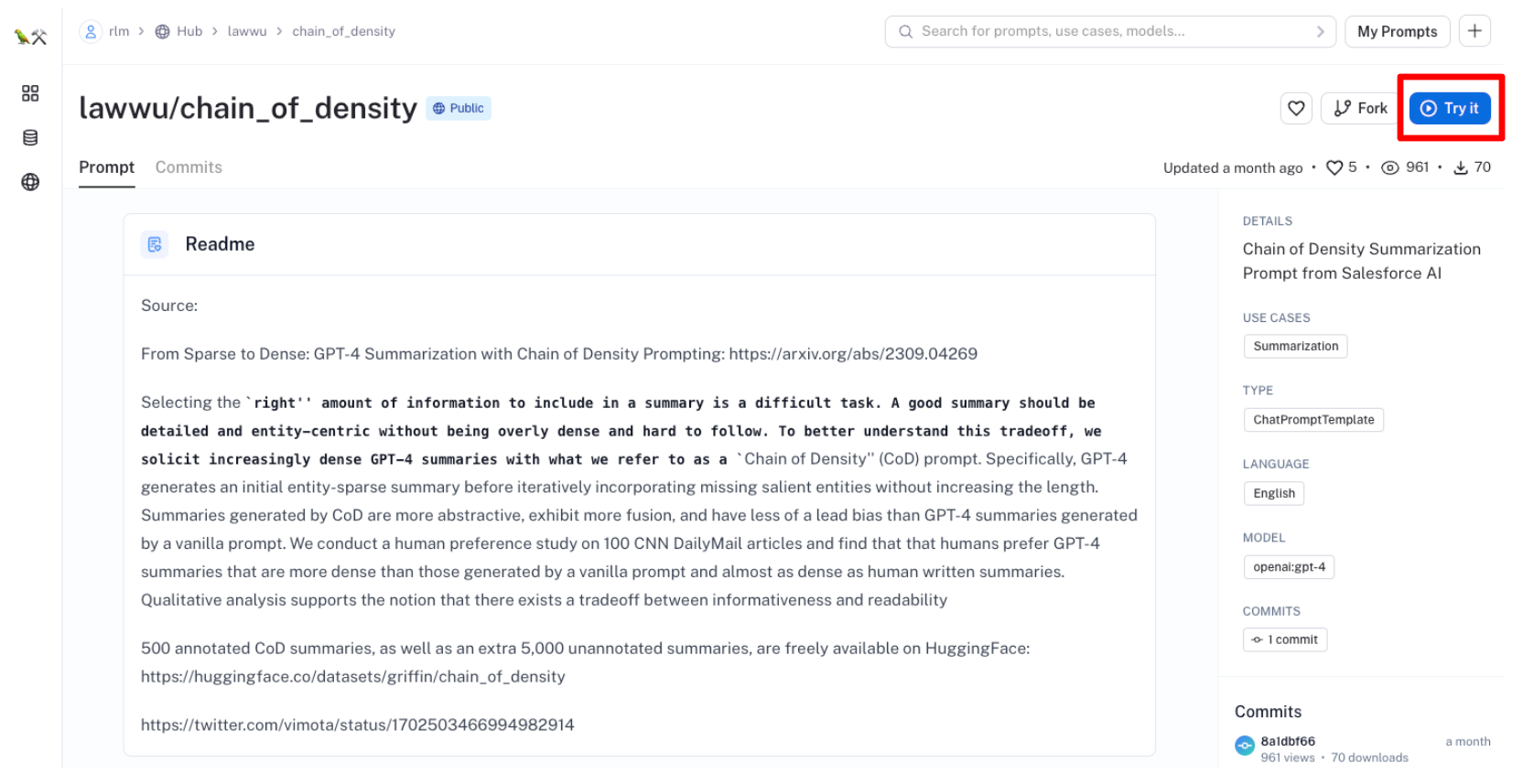
This will open a playground for workshopping and debugging prompts with a broad set of different LLMs, many of which are free to use: