Last week we launched LangServe, a way to easily deploy chains and agents in a production-ready manner. Specifically, it takes a chain and easily spins up a FastAPI server with streaming and batch endpoints, as well as providing a way to stream intermediate steps.
This week, we're making some additions – a playground and configurability. Both are centered around the same ideas: common architectures, experimentation, and collaboration.
Playground
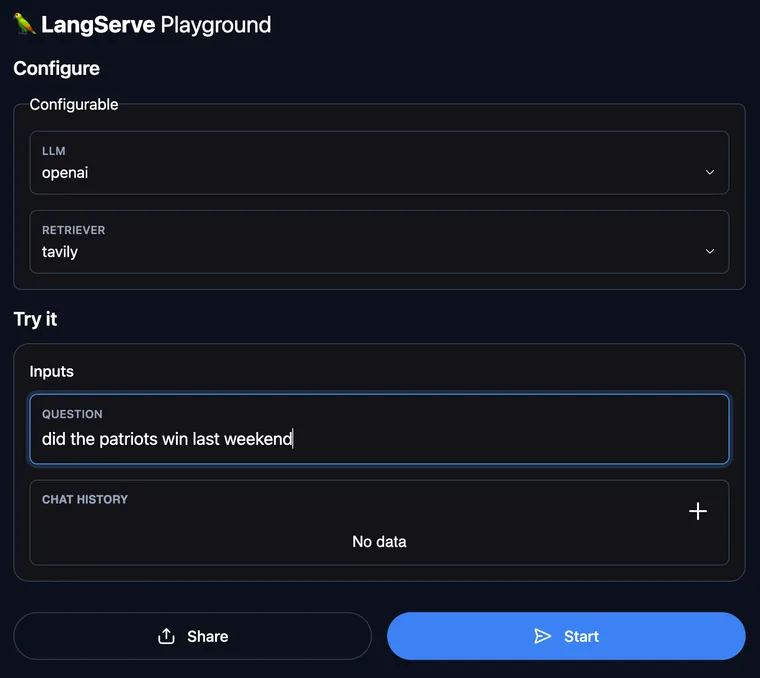
Now when you use LangServe to deploy your chain you get for free a playground experience. In this playground you can change the values of certain, configurable parameters (more on that later) as well as try out different inputs and get the response streamed back in real time.
The screenshot below is from a playground for WebLangChain, which you can access here.
Why is this useful?
First, this immediately provides a (simple) UI for your chains and agents. Although simple, this UI does have necessary things like:
- Streaming outputs
- Full log of intermediate steps
- Configurable options
This will make it possible to share a link with colleagues and let them interact with in the UI, facilitating collaboration among a larger team. Specifically, we imagine this being a way for engineers to easily expose a way for non-technical folks to interact with their chains/agents (without having to connect it to the frontend).
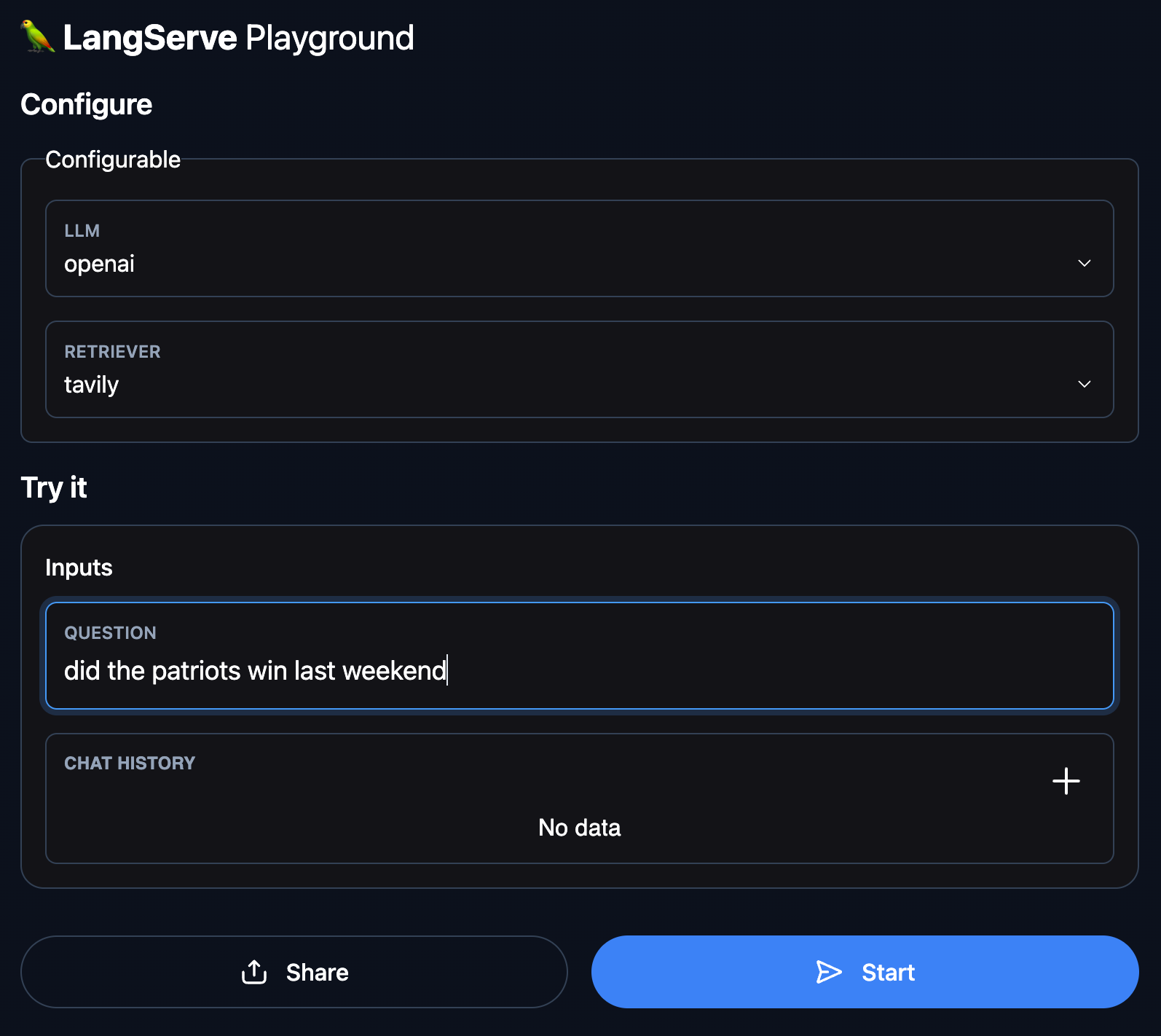
Second, this provides a way to experiment with different parameters. In the WebLangChain examples, we've exposed multiple different models (Anthropic and OpenAI) as well as multiple different retrievers:
This makes it super easy for any one - technical or non-technical - to experiment to different components.
Configurability
One new feature which makes this experimentation possible is configuration of runnables. Specifically, we recently added syntax to allow for any components (or parts of components) to be configurable. This is doable whether you are using LangServe or not - it's just part of LangChain Expression Language. See our cookbook for this here.
We've now exposed this configuration in a few places. First, as seen above, we've easily exposed this in the playground. However, this configuration can be used outside of the playground. We've also exposed it in our main WebLangChain app.
With configuration, you can save different versions of configurations via a URL. This can be used in a few ways. With WebLangChain, we expose this to the end user so that they can use that configuration in the UI. We imagine this more being used for internal apps, where you want to let internal users choose between different configuration options. We also expose this functionality in the playground, as seen below where you can copy a URL for a given configuration.
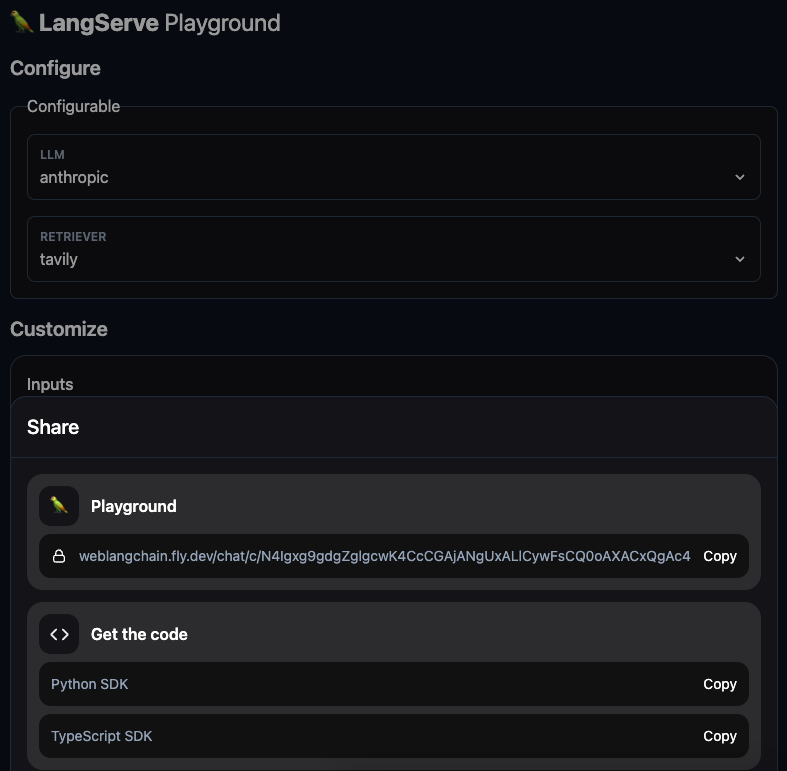
Note that for configuration options, the configuration is currently not persisted. We are currently alpha testing a deployment platform where the configuration is persisted - and can be persisted for multiple different users. If this is interesting to you, please reach out to sales@langchain.dev.
Common Architectures
We see that there are common architectures for LLM applications fast emerging. These architectures are fairly generalizable, and can parametrized in a few different ways. This observation is motivating a lot of this work.
For example, let's look at at our WebLangChain app from last week. This is a cognitive architecture aimed at retrieval augmented generation, and the ways it can be configured are:
- LLM to use to answer
- Prompt to use to generate the search query for followups
- Prompt to use to generate the answer
- Retriever to use to look up queries
We see that the architecture of the app often takes a lot of engineering to get up and running. But after that, a lot of the configuration is best done in some sort of GUI. This enables easier collaboration.
This insight - and belief that this is a good path towards application development - is driving a lot of our work in this vein.