
Editor’s Note: This blog post was written in collaboration with Zep, an early LangSmith BETA user. We've fielded a lot of questions about the latency of LangChain applications - where it comes from, how to improve. This is a FANTASTIC walkthrough of how LangSmith allows you to easily diagnose the causes of latency in your app, and how different components of the LangChain ecosystem (in this case, Zep) can be used to improve it.
Summary
Poor chatbot response times can result in frustrated users and customer churn. LangChain’s new LangSmith service makes it simple and easy to understand what’s causing latency in an LLM app. In this article, we use LangSmith to diagnose a poorly performing LangChain app and demonstrate how we improved performance by an order of magnitude using the Zep memory store.
Source code for this article: https://github.com/getzep/zep-by-example/tree/main/langchain/python/langsmith-latency
If you’ve ever waited several seconds for a web page to load and decided to click elsewhere, you’re not alone. Much has been written about the effect of slow websites and their impact on user engagement and conversion rates. Chatbot response times are no different. While responding too quickly may shove the user into an uncanny valley, responding slowly is problematic, too. Users will become frustrated and less likely to use your service again. They may also view the chatbot as unfair and be unwilling to share personal information.
Unfortunately, it's pretty easy to build a slow chatbot. Between multiple chains, high LLM latency, and enriching prompts with chat histories, summaries, and results from vector databases, a lot can impact how fast your bot responds.
Instrumenting and profiling your application can be challenging and very time-consuming. LangChain’s new LangSmith service does this fantastically and without any need to manually instrument your app. In this article, I will walk you through an example chatbot application that while simple, is not dissimilar to one you might be building.
My Chatbot is sooo slow
I’ve built a Chatbot app using LangChain, and my users are unhappy and churning.
The users would like to carry on a conversation with the bot and have it not forget the context and details of prior messages in a conversation. So, when building the bot, I used a LangChain memory class. I’m also using a Retriever, backed by Chroma’s vector database, to recall relevant messages from the distant past. In the future, I might also use a Retriever to ground my app with business documents. Like many Langchain developers, I’ve used OpenAI’s APIs for LLM completion and document embeddings.
Using the memory instance and retriever, my chain will inject the chat history into the prompt sent to the LLM. LLM context windows are limited, and large prompts cost more and take longer for an LLM to respond to. I, therefore, don’t want to send the entire chat history to the LLM. Instead, I’d like to limit this to the most recent messages and have my chain summarize messages in the more distant past. The prompt will look something like this:
LangSmith to the rescue
As mentioned, my chat app is too slow, and my users are churning. I really want to get to the bottom of why this is happening. In the past, I’d have to instrument the app in many different places to capture the timings of various operations, a time-consuming and tricky undertaking. Luckily, the LangChain team has already instrumented the LangChain codebase for us, and LangSmith makes it simple to understand the performance of your app. All I have to do is configure my LangSmith API key and add several descriptive tags to my code.
For my investigation, I put together a simple test suite using 30 messages, 20 of which are preloaded into the LangChain memory class and 10 of which I use in the experiment itself. Each run of the experiment passes these 10 messages to the chain. I do this five times so that I can understand experimental variance.
The results in LangSmith are below. Each run of 10 messages has a unique name and is the parent to several chain runs.
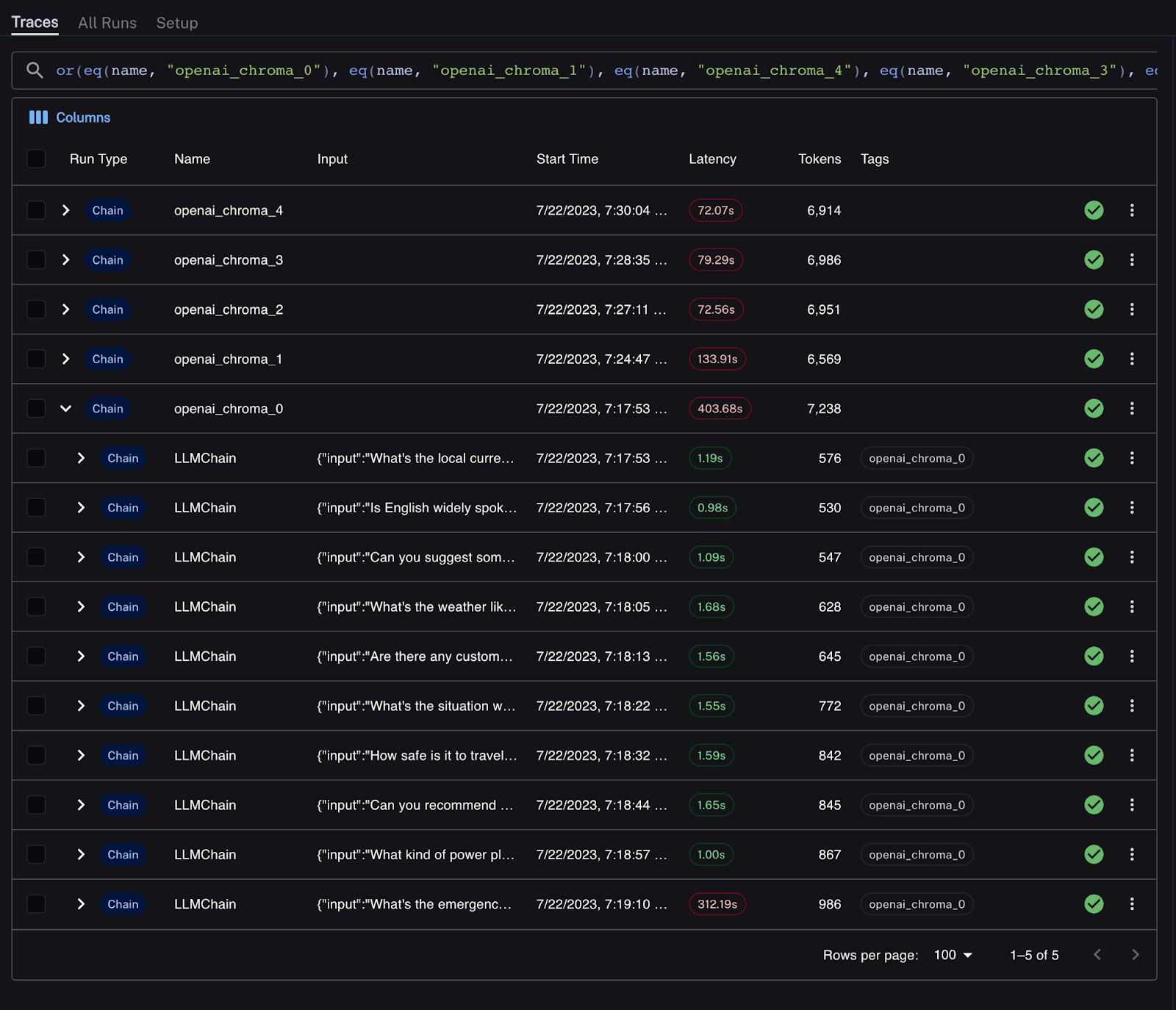
Latency is clearly visible in the LangSmith UI with poor latency marked in red. I can easily drill down into each run of the experiment to better understand why this is occurring. All experiment runs are slow, with a mean of over 7-13s to respond to each message. One of the runs is a significant outlier.

Drilling into that chain, I see a poor response time from the OpenAI API, taking over 5 minutes to respond to the request. It’s possible that the initial request failed and there were retries. Unfortunately, the OpenAI API can sometimes see rate-limiting and high variance in latency.
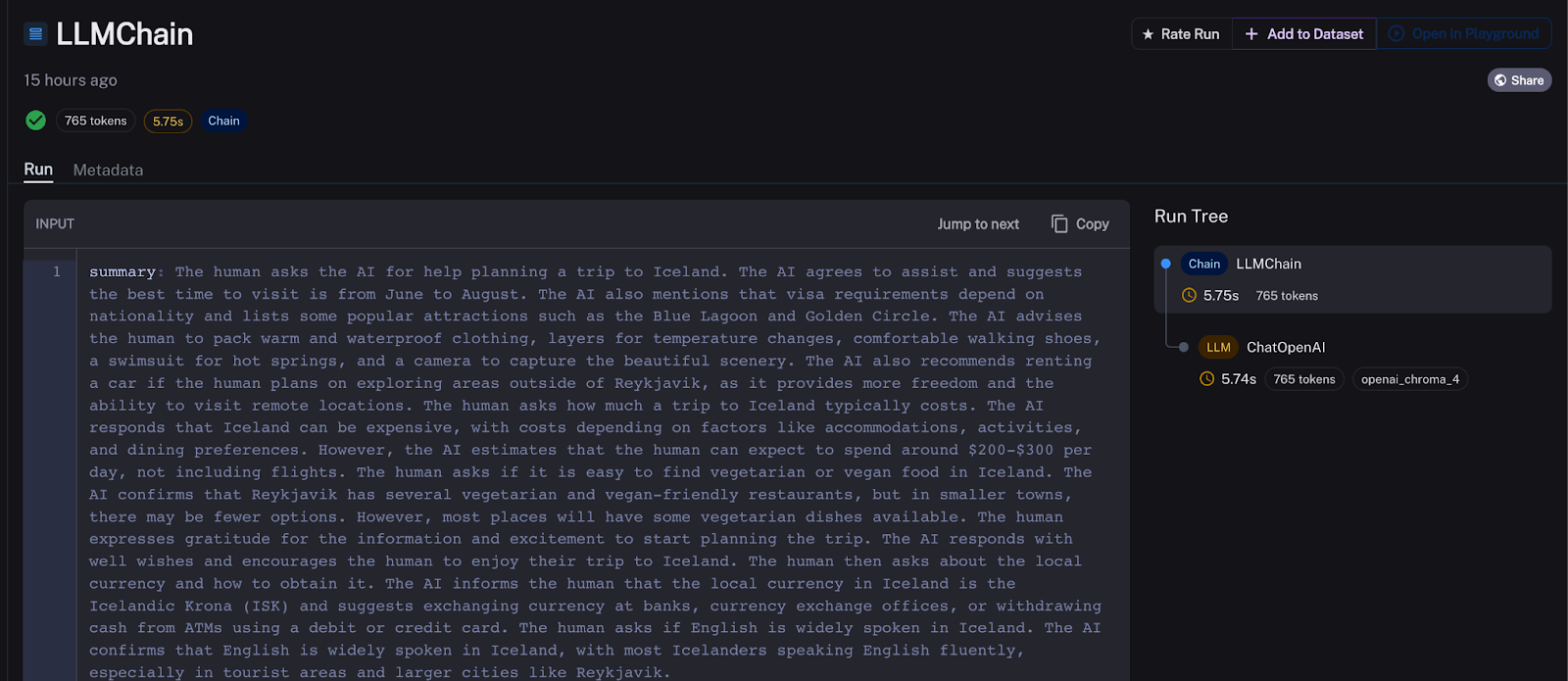
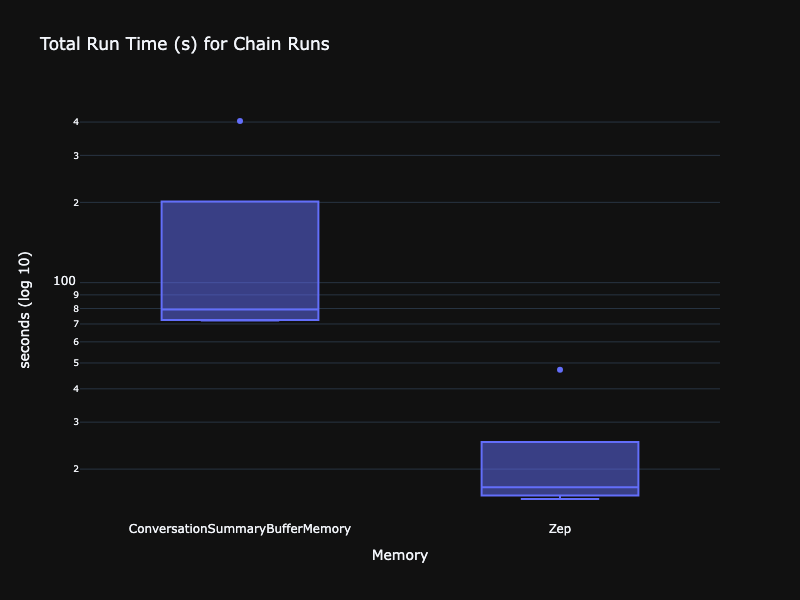
Let’s put aside the outlier and work to understand why each message turn of our chatbot is slow. I noticed that the majority of the time my chain spends responding to my users is the result of the ConversationSummaryBufferMemory’s summarization chain. For an arbitrarily selected response turn, summarization takes almost 6s of the 7s total response time. And this occurs every single time our chatbot runs. That’s not good.
Using Zep as an alternative memory service
Zep is an open source long-term memory store that persists, summarizes, embeds, indexes, and enriches LLM app / chatbot histories. Importantly, Zep is fast. Summarization, embedding, and message enrichment all happen asynchronously, outside of the chat loop. It also supports stateless app architectures as chat histories are not held in memory, unlike ConversationSummaryBufferMemory and many other LangChain memory classes.
Zep’s ZepMemory and ZepRetriever classes are shipped in the LangChain codebase for Python and JS and are drop-in replacements for LangChain’s native classes. Rerunning the experiment with Zep is super simple. I installed the Zep server using Zep’s docker-compose setup and modified my code.

I also don’t need to use a separate vector database for semantically retrieving historical chat memories. Zep automatically embeds and indexes messages.
The results in LangSmith are below. The total chain runtime for each experiment run is down to ~16 seconds, almost entirely explained by OpenAI API latency. Zep generates summaries in the background, which are automatically added by the ZepMemory instance to my prompt alongside the most recent chat history.
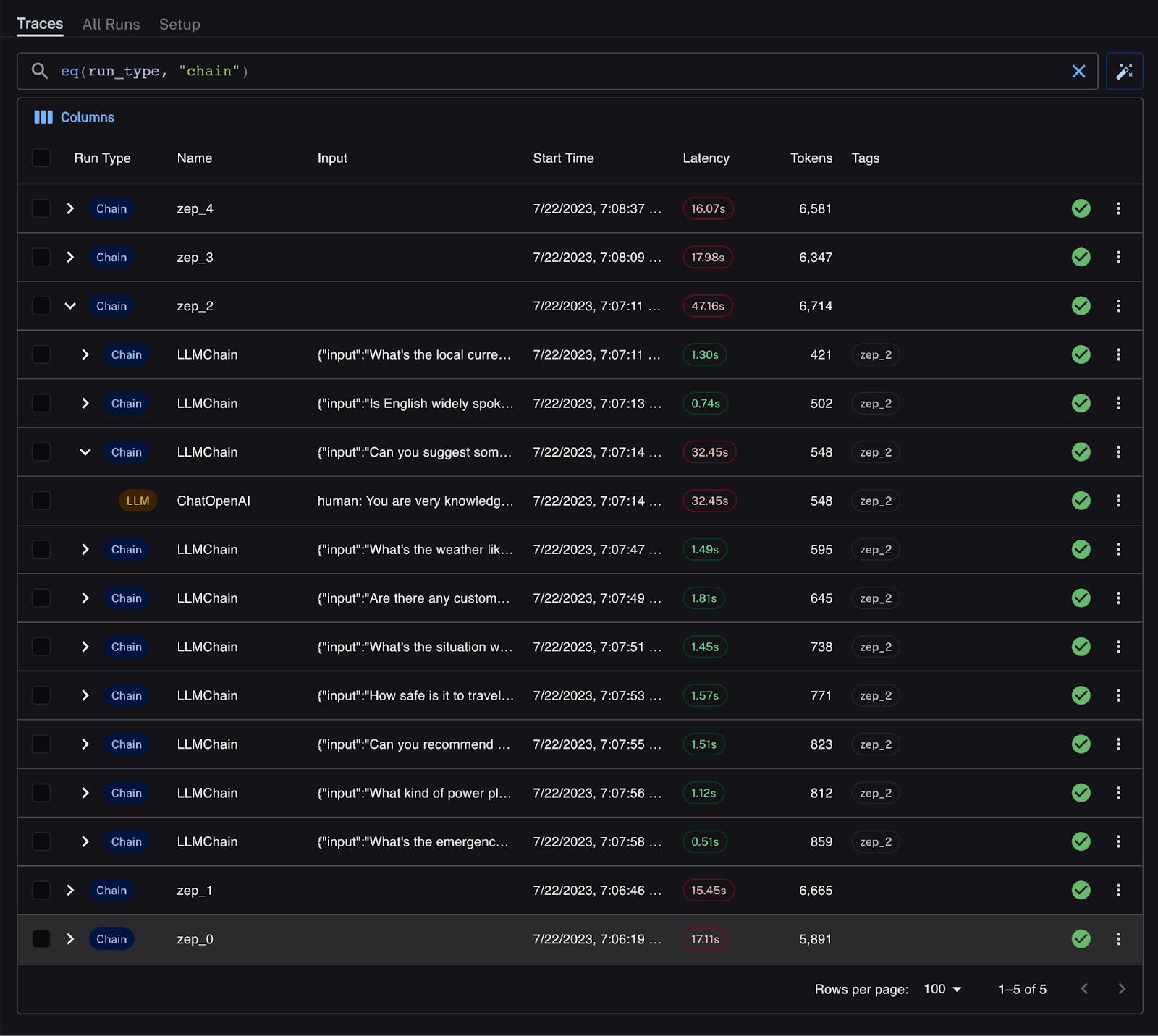
There’s an outlier chain run: OpenAI’s API spikey latency strikes again!
Let’s take a more quantitative look at the data. First comparing the distribution of run times, p95 and p99 for each experiment. There were 5 experiments, and we ran them for both chains using the ConversationSummaryBufferMemory and ZepMemory. The chart below uses a log scale for latency. As we saw above, Zep’s runtimes were an order of magnitude lower.

For good measure, I also analyzed the impact of the VectorStoreRetrieverMemory on the app’s response time below.
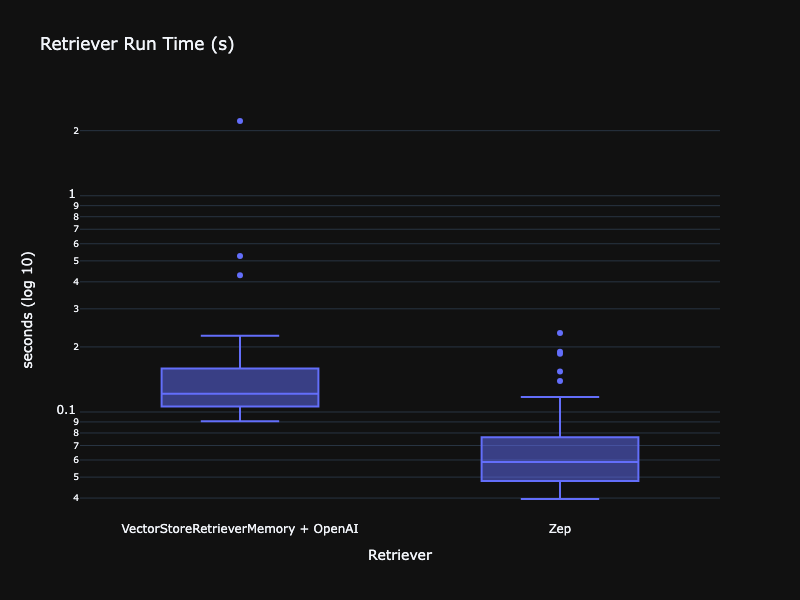
While certainly not as problematic as the ConversationSummaryBufferMemory, the VectorStoreRetrieverMemory and OpenAI for embeddings were still far slower than using the ZepRetriever. Zep can be configured to use a SentenceTransformer embedding model running in the Zep service, which offers far lower latency than calling out to the OpenAI embedding service.
Summing it all up
I’ve demonstrated how to diagnose LangChain chatbot app latency issues using the new LangSmith service. The culprit here was the ConversationSummaryBufferMemory implementation, which I easily swapped out with Zep, seeing a magnitude-level improvement in latency. LangSmith is a great platform for more than just diagnosing latency issues, with tools for testing and evaluating the correctness of chains and more.
Experimental Setup
I ran all tests on my Apple M1 Pro 14” 16GB RAM. For the Zep results, I ran the standard Zep v0.8.1 docker-compose setup with Docker configured for 4GB RAM and 4 cores.
The LLM used for all tests was OpenAI’s gpt-3.5-turbo and for embeddings, I used the OpenAI text-embedding-ada-002 model. For software, I used LangChain 0.0.239, ChromaDB 0.4.2, and Python 3.11.
All tests were run 5 times consecutively. All runs started with a new vector DB collection or index created from historical conversations. There was a short cooling-off period between runs.
Next Steps
- Sign up for the LangSmith beta
- Get setup with Zep using the Quick Start Guide