
Editors Note: This post was written by the NeumAI team and cross-posted from their blog. Keeping source data relevant and up-to-date efficiently is a challenge many builders are facing. It's especially painful for teams that are building on top of datasources constantly changing like team documentation (a use-case we see a lot of). Following up on our blog yesterday about making ingestion pipelines more production ready, we're really excited to highlight this because it continues in that vein. It adds scheduling and orchestration onto the ingestion pipeline, part of which is powered by LangChain text splitters.
Last week, we released a blogpost about doing Q&A with thousands of documents and how Neum AI can help developers build large-scale AI apps to support that scenario. In this post, we want to dive deeper into a common problem with building large scale AI applications: Keeping context up to date in a cost-effectively way.
Intro
Let’s set up some context first (see what we did there ;)). Data is the most important part when building AI applications. If the data you are training the model with is of low quality, then your model with perform poorly. If the data you are using for your prompts is low quality, then your model responses will not be accurate. There are many more examples on why data is important but it is really the fundamental part for bringing accuracy to our AI models.
Specifically here, let’s delve in context. Many have done chatbots where a massive prompt is passed to the model. This can become problematic for a couple of reasons.
- You might reach a context limit depending on the model you use
- The more tokens you pass the more costly your operation becomes
And so, people have started to include context in the prompt that is fetched depending on the user’s query so as to only pass a subset of relevant information to the model for it to perform accurately. This is also called Retrieval Augmented Generation (RAG). Those who have built this know what I’m talking about but if you aren’t you can check these two blog posts by Pinecone and LangChain for more information.

One problem not too many seem to talk about is how relevant this context is.
Relevant and up-to-date context
Imagine you are creating a chatbot over a constantly-changing data source like a restaurant’s menu or some team documentation. You can easily build a chatbot with some of the libraries and tools explained in the previous post - like LangChain, Pinecone, etc. I won’t go into too many details but at a high level it goes something like this:
- Get your source data
- Vectorize it using some embedding model (This is crucial so that whenever we bring context to the prompt, the “search” based on the user query is done semantically and fast)
- Bring the context to the prompt of your model (like GPT-4 for example) and run the model.
- Output to the user
This poses a trivial question. What if your source data changes?
It could be that the restaurant is no longer offering an item from the menu. That an internal documents or wiki was just updated with some new content.
Will our chatbot respond with high accuracy?
Chances are, no. Unless you have a way to give your AI model, up to date context, it probably won’t know that the pepperoni pizza is no longer available or that the documentation for onboarding a new team member to the team changed. It will respond with whatever context had been stored before in the vector store (or even without any context!)
Enter Neum
With Neum we automatically synchronize your source data with your vector store. This means that whenever an AI application wants to query the vector db for semantic search or bringing context to an AI model, the information will always be updated. It is important to note that the quality of your model also depends on how you vectorize the data. At Neum, we leverage different LangChain tools to partition the source data depending on the use case.

These are amongst the top things that are needed when building this synchronization for your LLM data.
- Setting up the infrastructure required to sync the sources
- Setting up your scheduler or real-time pipelines to update the data
- Handling errors if something goes wrong at any given point
- And most importantly, efficiently vectorizing to reduce costs
Now, let’s briefly talk about costs.
OpenAI embeddings pricing model currently is $0.0001/1k tokens. That might not look like much but at large scale, it translates roughly to 10k per 1TB of data. If your source data is not large, you might get away with it by constantly vectorizing and storing your data in the vector store.
But what if you have lots of documents? What if you have millions and millions of rows in your database? Vectorizing everything all the time will not only be inefficient but very costly!
At Neum, we’ve developed tech to help detect differences and only vectorize the necessary information, thus keeping the context up-to-date but in an efficient and cost-saving way.
See it to believe it
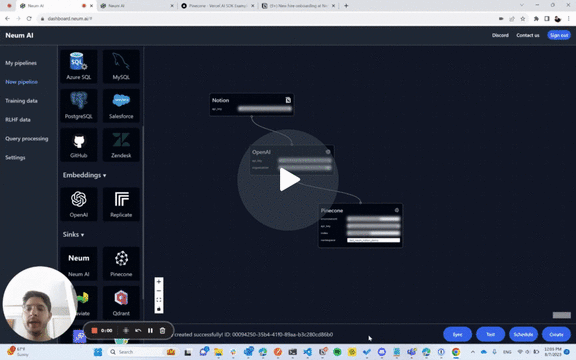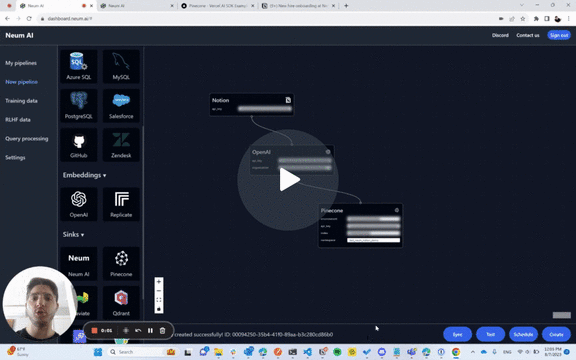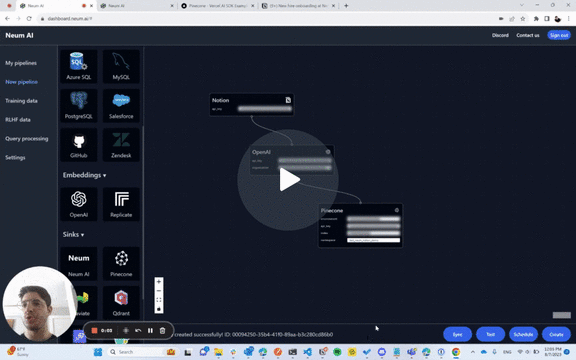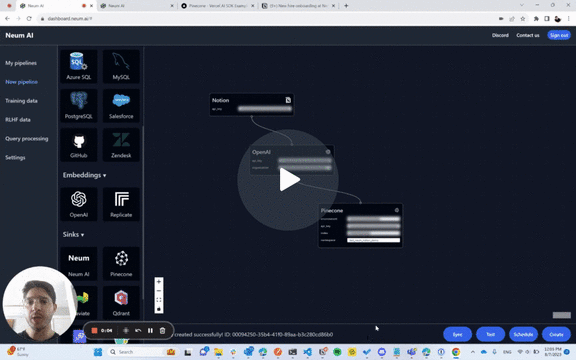
To prove this we created a sample chatbot for our Notion workspace that is updated automatically as the Notion is updated with more content. It allows users to as questions and get up-to-date responses if something changed internally. The sample is built with Vercel as frontend and Pinecone as the vector store. Internally, Neum leverages LangChain for its text splitter tools.
Behind the scenes, Neum is not only ensuring that updates are extracted, embedded and loaded into Pinecone, but also makes sure that we are only updating data that needs to be. If a section of the Notion workspace didn’t change, we don’t re-embed it. If a section changed, then it is re-embedded. This approach delivers a better user experience by having up to date data that is also more cost effective by only using resources where needed.
Take a look at the 2min video below for an in-depth look of how it works!
You can reach out to founders@tryneum.com if interested in these topics!